



I was recently introduced to the wonderful world of machine learning. A few Linkeding Learning courses and a few hours of dedication have been enough to understand what it is capable of doing, possible uses and even make a (very simple) model of automatic text classification.
Beyond a specific implementation, which we will see in a future article, the idea is to teach in broad strokes, what is the “magic” of Machine Learning and understand its possibilities and limitations.
What is Machine Learning?
As you can see in the diagram below, Machine Learning is a discipline within the branch of Artificial Intelligence.

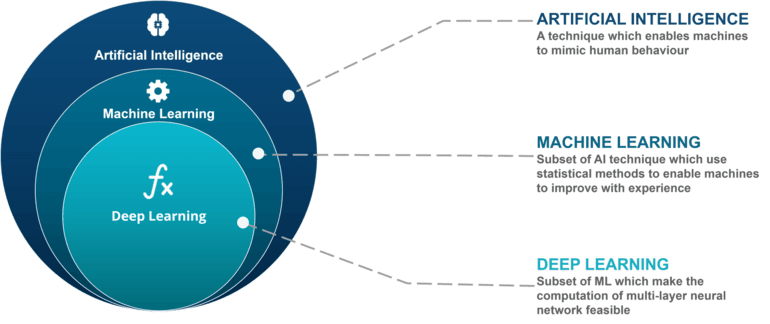
I think we can to summarize like it consists of the application of mathematical algorithms (especially statistics) in order to try to predict something based on its history. Surely with an example you see it more clearly.
Examples of using Machine Learning (ML)
Suppose we want to try to predict the (most likely) delay that a flight from Barcelona to Girona will have. You’d think you don’t need to make a model to find a pretty rough answer to reality, that you only need to make an average of the delays of this flight in recent months. Well, if we don’t have to be very precise, it might be enough, but if we want to fine-tune, we have to go further and observe more variables. Without going too far, it might be interesting to consider as well:
- Take-off time: Maybe the pilots are more tired at night than during the day.
- Day of the week: There are probably more passengers on Friday and therefore more delays can be generated.
- The day of the month: We could see if the number of passengers increases or decreases at the beginning of the month.
- The month: Depending on the time of year there will be more flights and therefore the speed with which they give us permission to take off or land will influence the length of the trip.
- The name of the pilots: A pilot may be more likely to be late, talk to passengers, be more skillful or less…
- Wind direction.
- The airplane model: whether it’s faster or slower. It’s been a long time since the plane was checked
As you can see we could take many variables into account and generally the more variables we observe the more reliable the prediction (there are mathematical methods to find out which variables have more relation to do with what we are looking for and in which the relationship is so weak that it is not worth having in consideration). With so much data it is no longer easy to calculate the flight delay and this is where an I.A. can help us.
In this case we should have structured all the data of recent years and go through the algorithms we have decided in order to train it and get a model that when we ask, for example, if the delay of a flight will be greater at 10 minutes we answer that the probabilities are X%.
We need to keep in mind that we need to ask “questions” that can be solved by the type of algorithm we have chosen and the data we have provided. Nor can we ask for a variable that we do not know (which is not among the data we have passed on to it) nor can we expect an exact numerical answer if the algorithm we are working with is only able to give us a percentage of possibilities.
Although it works by applying mathematical algorithms, computers only know how to work with numbers, using differents techniques practically everything can be transformed into numbers. For example, by assigning numbers to words, we can apply ML techniques and algorithms to texts so that we are able to classify texts (tweets, press articles, “papers”…) or by understanding images as arrays of pixels in which the color of each of them it’s represented by a number.
Difference between Machine Learning and Deep Learning
“Learning” by a model Machine Learning can be classified into two main groups: supervised and unsupervised.
- Supervised: When it requires that the data necessary to train the model must be previously tagged or completed by a person. During this process it is necessary for a person to indicate to the model which variables to use. For example, for the text classifier exercise, we must have a sample of texts that have been previously classified by a person so that we are indirectly indicating to the model how many categories of texts we have and the type of these there are in each group.
- Unsupervised: In this case we would train the model with “raw” data therefore there would be no human intervention to classify or add value. This type of learning is mainly used to discover groups and relationships between variables. In our case to group texts, a good “deep learning” algorithm would be able to group them without a person having previously tagged thousands of texts. Obviously I would not know what each group is called (we are not passing neither the name of the groups nor the type of text in each group), but I would be able to group them according to the text of each one of them.
In the last decade AI has evolved a lot thanks to the use of “Deep Learning”. It continues to work based on mathematical algorithms but in much more complex and layered combinations. It is the approach that, until now, more accurate imitates the behavior of the human brain and is used to being represented as a network of neurons (neural network).

The first layer represents the input variables and in the subsequent ones, algorithms are applied to each of these input variables to finally combine all these data in a way that gives a single result. The most classic example is object recognition.


Stages of a ML project
As I mentioned at the beginning of the article, to get a more concrete idea of what we are talking about, we will comment on a very simple text classification model that we could apply to categorize incidents.
Like any project, it is recommended to follow a series of stages to minimize possible errors and maximizing the chances of success:
- Definition of the objective.
- Collection and preparation of data.
- Choose the model.
- Model training.
- Model evaluation
1. Definition of the objective.
Let’s imagine that we work with a central software where all the incidents of the company are received, from the request that for the creation of a new user to the system until the request claim about an error in a payroll. To facilitate the screening of incidents and that the specialists only receive the incidents that belong to their field of knowledge, all incidents will be previously classified into themes / queues.
The objective is to create a ML (supervised learning) model that is capable of finding out which topic / queue a new incident belongs to. As it is supervised learning, we must have a sufficiently large number (of the order of thousands) of examples to provide the model to learn what type of incidence each queue.
2. Collection and preparation of data
Before providing the sample data to the model, we must make sure that they are in a format that is easy to read for the computer.
Data quality
All the values for the same variable must have the same format and the same structure (normalize):
- In case of having numeric fields, all the values of that field must be in the same format, unit and scale.
- In the case of texts, we will have to avoid rich text or that the text to be analyzed is mixed with HTML, XML tags, etc.
For example, in the previous example that was trying to guess the delay of flights, if we had a field that reports the delay of flights, which has been reported by different people manually, we could have values as disparate as:
- 12 min
- 12min
- 12
- 720 segundos
- 720sec
- 00: 12: 00h
The model will only understand the “12” and will not know what to do with the rest of the values of that variable
In order not to complicate the example and to be able to focus on what really interests us, we imagine that we have already done a large part of the normalization work of the texts and that we have downloaded all the incidents in a CSV where at least the following fields appear:
- The description of the incident.
- In the category / queue to which it belongs.
3. Choice of model
Currently there are 3 main types of models:
- Binary classification: to tell if something is true or false.
- Multi-class classification: prediction of a value from more than two possible values. For example a customer’s favorite dish.
- Regression: predicts a specific number, for example the number of goals your soccer team will score in a specific match.
Within each model type there are different possible mathematical algorithms. For example, there are different algorithms to find a customer’s preferred dish and it will depend on the approximation you want to make and the data you have, the algorithm generates better or worse results.
4. Train the model
Now, we have everything ready to start programming the model’s training.
The most popular languages to create Machine learning projects are R, Python and Java. I recommend you start learning ML in Python since it is the most practical to take the first steps since there are many libraries that help a lot and a very large number of examples and documentation.
In addition, there is the JupyterNotebook project that allows you to program Python from a web interface, you can execute the code for lines so that you can execute only a part of the code as many times as you want but keeping the states of the variables and objects with the values obtained from the previous lines without having to run -las again. This is very practical when working with operations that can take a long time to execute, such as ML projects.
So far the theoretical part of the example. If you want to see a very simple Python implementation of an issue classifier model, I have written an article on how to do it using NL (Natural Language).
Conclusion
We have seen that technology is at a point that allows us to predict much better than with classical techniques. There is already a lot of documentation and tools that “democratize” access a lot and that therefore it is worth including it without “fear” in projects that may benefit.