

As I mentioned in the previous post, we are going to “land” a practical example of how to implement a simple text classifier, more specifically an incident classifier
Choose language
Returning to the previous article, the best known languages to create Machine learning projects are R, Python and Java. I don’t know much about R but it seems less versatile than the other two. On the other hand, although Java is well known and robust, I have found more content about ML in Python and I also believe that it is more practical to take the first steps (less structure to modify in each trial / error iteration) therefore we will choose this language for learn.
In addition, there is the JupyterNotebook project that allows you to program Python from a web interface, you can execute the code for lines so that you can execute only a part of the code as many times as you want but keeping the states of the variables and objects with the values obtained from the previous lines without having to execute them again. This is very practical when working with operations that can take a long time to execute, such as ML projects.
The data
In our example, we will have a CSV file with more than 80,000 correctly categorized incidents.
We could also add the field that informs the person who has written the incident it can help us to know what type of incident it is because usually a worker puts similar types of incident. For example, a warehouse worker, due to the type of work he does, will be more likely to make an incident to the maintenance department than the accounting department.
The file will have the following structure:
caller_id: Name of the person who wrote the incident.
short_description: Issue subject or short description.
description: The complete description.
assignment_group: Category or queue to which the issue is assigned.
As we talked about in the previous article, the quality of the data is very important. In this case it has not been necessary to clean up, but if the software saves the text in some kind of rich format (for example HTML) before advancing and training the model, we should polish the data.
After testing different algorithms (we will not go into the tests performed in this article), in our example we will use the multi-class classification algorithm called “Linear Support Vector Classification“
Beginning lesson
The first thing to do is read the training data, in this case incidents
import pandas as pd
import csv
df = pd.read_csv("DataSets/TOTES_LES_INCIDENCIES_v4.csv", encoding = "ISO-8859-1")As you can see, we have to install and import the Panda libraries, well known to Python programmers. These will allow us to create a DataFrame (object to manipulate data obtained from a structured data source) with the data read from the CSV file where we have all the incidents.
To avoid data inconsistencies taking into account incomplete data, lines that do not have all the fields reported are deleted from the DataFrame.
df = df.dropna(subset = ["caller_id","short_description","description","assignment_group"])
In order for the model to take into account the name of the person who created the incident, we will create a new field in the DataFrame where we will join the name of this person with that of the description text. This is the field with which we will work from now on.
df['concatenat'] = df['caller_id'] +'.\r\n'+ df['short_description']
Since the computer only “understands” numbers, we must assign one to each category / queue. The model works with these identifiers and only when we want to show the results can we re-relate these identifiers with their corresponding description.
To do it correctly we must do it with the factorize function of the dataFrame that will create a new column in the DataFrame with the number that corresponds to the category to which the incident is assigned.
df['category_id'] = df['assignment_group'].factorize()[0]
Before we start with algorithms we will reduce the number of words you will have to work with.
First a lambda function to convert all uppercase to lowercase so that the same word with or without capital letters cannot be interpreted as two different words.
Then we will use the Spacy library to obtain the list of STOP_WORDS corresponding to the language of the text, in our case, Spanish. This list contains articles, frequent greetings, punctuation marks… words that we will extract from the text in order to optimize the training of the model.
from spacy.lang.es.stop_words import STOP_WORDS as es_stop
from io import StringIO
import string
df['concatenat'] = df['concatenat'].apply(lambda fila: fila.lower())
final_stopwords_list = list(es_stop)
final_stopwords_list.append('\r\n')
final_stopwords_list.append(string.punctuation)And now we come to one of the most important parts of training a Natural Language (NL) -based ML model, the transformation of words into vectors of numbers. In this case, the best algorithm we have found is to do it based on the frequency in which these words appear in the text. For example, for text 1 we will have a vector where each word occupies a position in it and the value of this position is a value between 0 and 1 that indicates the frequency in which it appears in this text.
tfidf = TfidfVectorizer(sublinear_tf=True, min_df=5, norm='l2', encoding='latin-1', ngram_range=(1, 2), stop_words=final_stopwords_list,max_features=5000) features = tfidf.fit_transform(df.concatenat).toarray() labels = df.category_id
Of the parameters that we pass to the constructor, it is worth highlighting:
- ngram_range = the range of word sets that we think have meaning to themselves. In this case we are indicating that it analyze sets between 1 and 2 words.
- stop_words = list of words that we do not want it to analyze in order to optimize the process and not be contaminated by words that do not help to classify the text.
- max_features = maximum size of the vector of words analyzed by each text. If you have little RAM you can try reduce this parameter.
Finally, we prepare the names of the different categories where we want to put our texts in associative vector
Now we have the data ready to train the model properly. For this we will use the most famous ML library in Python, Sklearn. For this example, we are interested in two things about this library:
- The train_test_split function: allows us to easily divide all the previously classified incidents into two groups, a group that will help us to train the model and another group that will help us to test the model after being trained and will indicate how good the model is classifying incidents. As we will see in the example we have stipulated you to test the model with 20% of the data so that the other 80% will be used to train the model. Obviously we will have to pass both the incidents and the groups in which it has to be classified. As we can see, this function returns 6 vectors, three for each set of data.
- The algorithm that we will use to classify the incidents: In this case the one with the best results I have obtained is the LinearSVC.
All the algorithms in the library have a “fit” function in which we have to pass the two training data vectors to it. Once the model is trained, we will call the “PREDICT” function that will test the model with the incidents of the test group. This will allow us to assess the efficiency that we have achieved with this classification algorithm and the configured parameters.
from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVC model = LinearSVC() X_train, X_test, y_train, y_test, indices_train, indices_test = train_test_split(features, labels, df.index, test_size=0.2, random_state=0) model.fit(X_train, y_train) y_pred = model.predict(X_test)
As you can see, these libraries greatly facilitate the task since they incorporate many algorithms and standardize the code to use them.
Model evaluation
We can finally see the result of all the previous work. First we will obtain a list of the names of all the categories / themes in which the texts could be classified and later we will make a “print” of the table of metrics corresponding to the results obtained.
from sklearn import metrics
unic_label_train = df.groupby(['assignment_group'])['assignment_group'].size()
unic_label_train = unic_label_train[unic_label_train].index.get_level_values(0).tolist()
print(metrics.classification_report(y_test, y_pred,
target_names=unic_label_train))We will get a table like this (I have hidden the actual category names since I am using a private dataset)
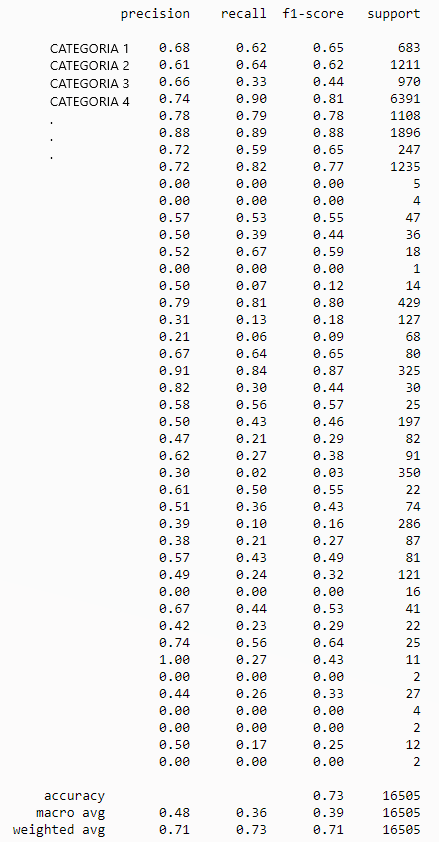
At a glance we will see two sections, the upper part where for each category we will have its specific metrics and the lower part where we have the general result. The meaning of the different columns is this.
- precision: It is the ratio between the correct predictions and the total number of predicted correct predictions (precision when predicting positive cases)
- recall: It is the relationship between the correct positive predictions and the total number of positive predictions.
- f1-score: the average of the previous two, would be the general score of how good the model is in its task.
Therefore we can verify that we have achieved a general efficiency (accuracy) of 73% in a very simple way.
If we stop a little we will see that for some categories, we have a very low efficiency. This can be due to different problems:
- There are not enough incidents in this category and therefore the model has not been trained well enough to identify them.
- The texts of the incidents between some categories are very similar and it is not able to correctly distinguish which group it belongs to.
- Unspecific texts (they contain few “key” words)
- Lack of optimization of the parameters configured in the algorithm.
Look that in the training of the model we have left the default parameters of the algorithm. Normally the default values are those that offer the best average values, but if we wanted to go deeper and get better results we should study what each of the algorithm’s parameters (in this case the LinearSVC) does and try to find the best combination of these. There are automatic methods that by “brute force” indicate you the most optimal combination of parameters but I only recommend them for projects that go to production since finding a better combination requires a large amount of computational resources and time. To make an approximation, the default parameters give good results.
You can find the whole code in my GitHub repository.
Conclusion
As we have seen, large projects are not needed to be able to apply Machine Learning techniques, they can be very modest projects, but what we will need is a lot of example data.
This was just a very simple example that is practically done “alone”, you just have to prepare the data a little, “concatenate” a couple of functions from the libraries and see the results. Thanks to the libraries that we have installed, by changing very few instructions we can try different algorithms and see what offers us the best results for our case.
It may come as a surprise that we didn’t need a lot of statistical knowledge. The libraries that we have used already incorporate the most useful algorithms and that will surely cover a good part of the possible use cases. Anyway, if we wanted to “play” with the data, compare algorithms, refine the predictions, etc. we would have needed a good knowledge of statistics.
Finally, if you want to see more practical examples, there is Kaggle that is a website where companies or individuals can ask for help in real “machine learning” projects and the community can help them in a disinterested or interested way (companies frequently reward individuals who has provided a solution to the problem posed). Normally the code is shared publicly on the platform so that it is useful to the rest of the community and therefore it is a very interesting source of knowledge.