



You’ve probably had a chance to try the GPT chat since it’s been in the news around the world for the spectacular leap it represents compared to previous models. It is undoubtedly a very powerful and revolutionary tool, so much so that the CEO of OpenAI (Sam Altman), the company behind the GPT Chat AI (GPT-3) and Dally-2 acknowledges in an interview (part one and second part) that before releasing any model they think very carefully about the impact it will have, because they prefer that this technology “digests” in a staggered way by society. Without a doubt, they have been working on GPT-4 for some time, although according to their words, it will not have such a significant increase in input parameters as some images that run through the networks lead to believe.


As I am writing this article on January 29, 2023 and no newer version of GPT is available yet, I can only comment on my impressions of GPT-3.
General considerations
It is necessary to warn that the intention of this article will focus especially on the use of the GPT3 model for code generation.
On the other hand, if you take a tour of my website, you will surely have realized that I like programming and that I have knowledge, so when using the tool, I am starting from the point of view of a person accustomed to developing programs and with a mind structured by this task.
The tests arose from the real need to make an application that was intended to save me work when it came to allocating the hours I dedicate to each client. The idea was to create a program in Python (a language I don’t know) that every time it was executed, passing the name of a client as a parameter, it would save the current time. The first time it was run for a specific client the date would be the start time and the second time the time would be the end time. These data had to be saved in a file with a .csv extension (for using free standards). It really is more complicated than that, but it was still a program that a “senior” Python programmer wouldn’t take more than an hour to make.
Given the buzz around the output of Copilot (an integrated GPT3 model in GIT that allows you to generate code from code comments written in natural language) I wanted to test for myself the uses and limitations of this model (and depending on the results start to redirect my professional career XD)
Generation of small entire programs
I started with a simple version of the program since I didn’t have much experience with Python, let alone using GPT chat. In these cases (programs of about 10 or 15 lines) the truth is that they worked correctly. The functionalities that it did not do were attributable to the fact that it had not described them and therefore it would have been really “magical” for the model to create them correctly. For example, it told it to read a file with a .csv extension and add a line with the value passed by parameter and the current time. The result was a program that did exactly what was said, but did not check that the file where the data was to be stored existed, nor did it expect the parameter to be passed from the command line, but instead the generated code was encapsulated within a single function expecting an input parameter, but you certainly hadn’t specified either to it, hence “my fault”.
Describing the shortcomings that I was seeing in the code that I was generating, we arrived at a code that worked correctly but did not have all the functionalities that I needed for my purpose implemented, so I raised the difficulty. In order to automate the time calculations, I had to put the customer name, start time, and end time on the same row. Therefore, the application, before adding a new line with the current time, had to check that there was no line that started and did not end with the client name that was being passed to it as a parameter (a line with the client’s name and start time but no end time). I also wanted a first line as a header where the names of the columns would appear. And this is when I no longer achieved such good results.
Errors of all kinds:
- It only wrote the header if it had to create the file, but if it had to modify/overwrite, the header would no longer appear.
- It didn’t always check that the file it was supposed to write to already existed
- Bring together different ways of manipulating data in the .csv file that are incompatible with each other
- Sometimes it would leave part of the program unwritten.
- Overwritten the csv file with the last line instead of adding it to the content.
- Blank lines were left in the .csv file which caused the program to think that the file had fewer lines than it actually did when reading the file.
However, I must admit that I was pleasantly surprised:
- Although it’s just translating the text into English before applying it to the model and doing the “trip” in reverse when the answer is displayed, I liked that I was understood in my native language (Catalan). li>
- That the comments and names of the variables were in the same language in which I was describing the program (not in all iterations this was the case). Taking into account that millions of programming lines were used to train the model and that an overwhelming percentage would be in English, it was a fact that pleasantly surprised me.
- The number of comments the code had
- In most cases the code was well structured (declaring the constants at the beginning, breaking the code into meaningful functions, not repeating functionality…)
After investing a lot of time, I ended up discovering that I was not able to move forward and that it was taking much longer to regenerate the result that the tool offered me (sometimes it was so bad that it didn’t even stop generating it) than it would have taken me starting from 0 and asking StackOverflow the doubts. In addition, searching the internet for any of the “nomenclature” doubts that I had, I saw that “those who know” would not do it as I was trying to do (with the basic Python instructions) but the most optimal thing was to do it taking advantage of the power of the Pandas library.
Admittedly, I took advantage of the proposed structure, but I don’t think I left more than 5-10 lines untouched (counting variable declarations and amounts) . And this is where I understood that someone who has had practically no contact with the language can give them a starting point since they can observe the syntax that the language uses or can even give an idea of how to structure the program (order, functions etc).
Use as expert
As I mentioned before, in most iterations it generated a code that left blank lines in the CSV file that I wrote. Once the GPT-3 model to generate simple programs was discarded, I decided to continue testing it but changing the approach. I would no longer expect it to generate all the program code for me, but would use it solely to solve the problems I had with the operation. So I asked how I could solve the problem with the blank lines appearing in the CSV file.
The answers he gave me, despite making sense, did not help me, since it was very limited to what I had described to him (“because when writing a Python text file I may be leaving two blank lines at the end of the file?”)


As you can see the answers, despite being well argued, focus on the use of the “write” function and the “print” function. Although I asked you to generate more answers for the question, they were all very similar.
Eventually, I ended up looking on StackOverflow and found an answer that said that the key was the “newline” parameter in the statement that is used to open the file in write mode. In my humble point of view, it is a solution/proposal that GPT-3 should have given me since it is an answer based on the official Python documentation and is not derived from the complexity of a specific functionality or something particular in the program. Also, none of the codes that he had generated for me included that parameter.
Use it to generate concrete examples
When I started developing the program using the Pandas library, I added another degree of complexity, since now I should know how the functions and objects of this library work.
When I asked him why using the “read_csv” function added a new column to the DataFrame or how to compare a specific position of a DataFrame with a null, he generated basic, but very useful codes for me much faster than searching on Google.



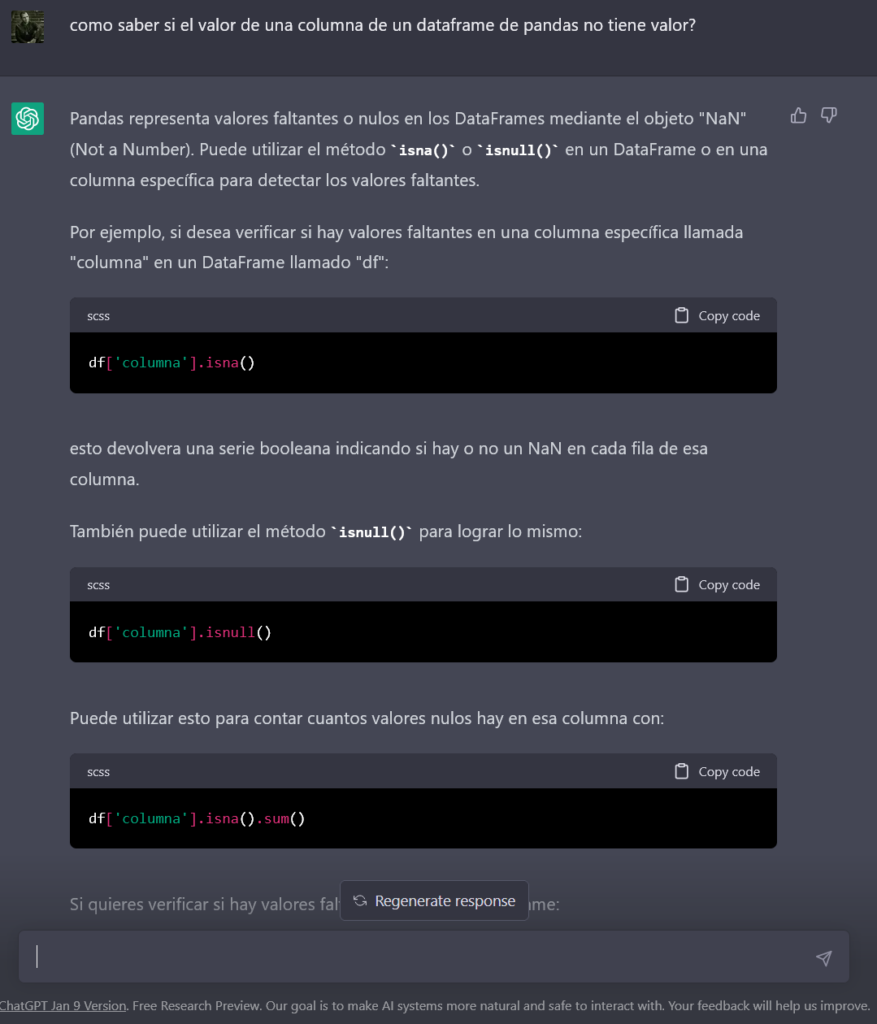
Therefore, for this use (asking for very specific things) yes, it is effective, but to ask this type of question you must have a good knowledge of what you need (basically solved “syntax” doubts). p>
A very clear example that this is the most appropriate (in terms of code generation) is the GitHub Copilot service (also based on GPT-3), which generates code from the comments you put in your program. The mechanics are very simple, you write a comment that describes a very small portion of code (a “loop”, a conditional or a simple function) and the service proposes a code that must comply with the functionality described with the comment.


It is also capable of proposing the code immediately following the one you are writing, thus saving you time and possible errors.


Conclusions
Although the tests have been based on a single program, I think they give an idea of the current limitations of this model in terms of code generation.
The model has been trained with millions of lines of code and this has given it the ability to correctly solve very specific questions, but although it is surprising that it does so in a well-structured way, it still fails to put all the pieces together.
The GitHub Copilot service alone represents a breakthrough and no place Undoubtedly, GPT-3 is surprising, extremely powerful and we must take advantage of it in everything that can solve us, but we must be realistic and understand that its current possibilities are far from creating functional code by itself based on a detailed description of the functionality. In a short time, it will greatly reduce the technical debt that can be had in some technologies in such a way that it reduces the difference between a person with a lot of experience in a specific language and another with less experience in that same language. What’s more, the day could come when even the least open companies, when looking to fill a vacancy, related to IT, stop demanding so many years of experience in the specific language and learn to value general experience more 😉 p>
For all this, I think that today it should be understood as a very good help, but that it is far from being a solution that meets the needs of developers.
Although it is not the case of the OpenIA models, I leave you a “meme” about how some companies sell us AI and what is behind it 😉

