



Introduction
I’m continuing my tests with the GPT Plus account, and this time I wanted to understand in more detail the process followed by an AI model to answer questions related to documentation we provide and understand the complexity/challenges it entails. In recent months, a very effective method called RAG (Retrieval-Augmented Generation) has become popular, and it’s time to get hands-on with it.
Objective
First, my intention is for the model to respond with data from my web articles. I don’t have many, but they are of a length similar to what a medium document could be.
Later, we will try to do this with longer and less structured documents to get closer to a “real” case where a small company wants to use an AI model for their employees to obtain information from corporate documents.
Requirements
Well, you will see that for the easy method (using the libraries with chatGPT models) GPT plus account, and obviously the documents you want it to answer questions about. When we see how to do the same with open-source models, you will only need to have an account on Hugging Face.
For the test with structured documents, I will need the URLs of my previous articles, but you can really do it with other JSON documents you have. For the test with unstructured documents, I downloaded the Telefónica results presentations for the last 4 years, but any PDF file will work.
You will also need a Python programming environment (the language par excellence for working with AI). I used Jupyter Notebook, which is very practical for this type of test, but you really just need to install Python and have an application that allows you to create/modify a plain text file.
Understanding the “Memory” of an LLM (Large Language Model)
Before delving into the subject, it is necessary to understand how the “memory” of LLM models works. Although I did not mention it in the previous article (where I talked about how to create a personalized GPT chat), you can also attach documents to GPT agents for them to consider. However, all the information/personalization you use to configure your agent actually serves as the header for your future “prompts” (questions) every time you make one.
“You are a virtual assistant who will help me with daily tasks, including creating events and reminders in my Google Calendar. Create an event in the calendar for next Friday at 9:30 am with the title ‘Create a new article on the web'”


An example will make it very easy to understand. Let’s imagine that in the agent’s configuration you told it “You are a virtual assistant who will help me with daily tasks, including creating events and reminders in my Google Calendar”. Once you have it configured and want to ask it “Create an event in the calendar for next Friday at 9:30 am with the title ‘Create a new article on the web'”, what you are really saying is:
This “prefix” is called “context”. And this works perfectly, but models have limitations in terms of the number of tokens/words they can hold in context. The newest ones (GPT4o) could have a book of about 300 pages approximately as context, which is clearly insufficient to fit even all our personal information (emails, legal documents, invoices, etc…)
To avoid this limitation, we have 2 alternatives:
- Vectorize the documents into “embeddings” (data vector).
- Make the documents part of the data in a “fine-tunning” process (re-training the model).
In broad terms (I will explain it in much more detail later), what we will do in the first alternative is to ask an indexing algorithm which document(s) are the most relevant for the question we are asking, retrieve the relevant portion of the document(s), and pass it as context to our model so it can extract the necessary information to answer us.
The second method works completely differently. It involves doing a small extra training on the AI model so that it “memorizes” the documents. This allows us not to worry about passing a part of the documents as context to the model, but the model will “memorize” the documents internally. It has a higher computational cost and the disadvantage that you are training it with the content of the documents at that time, so if you ask questions about information contained in “live” documents, it will respond with outdated information.
You should keep in mind that companies offering cloud inference services with AI models usually charge by the number of input tokens (context + prompt) and output tokens (the model’s response), so the second option is more efficient in this regard.
The best strategy when implementing AI for both domestic and business use would be to do a “fine-tuning” of everything that cannot change (historical) but to vectorize the rest of the information.
Preparing the Data
Surely the most complicated part of the whole process is polishing and transforming the data. Although these processes are not mandatory, they are highly recommended to obtain better search results.
To run tests with structured documents, such as articles from my website (and I write fantastically well 😉 ) and not very long, it won’t be necessary, but usually, you should look out for these points:
- Removing special characters and punctuation: Remove characters that are not necessary for analysis, such as excessive punctuation, emojis, or non-alphabetic characters.
- Spell checking: Correct spelling errors to ensure text consistency.
- Text normalization: Convert all text to lowercase to avoid differences caused by uppercase/lowercase.
- Duplicate documents: Remove documents that are exactly the same.
- Duplicate fragments: Remove paragraphs or sentences that are repeated within the same document or between different documents.
- Thematic relevance: Ensure that the documents are relevant to the topic of interest.
- Quality: Filter out documents with little information, too short, or of low quality.
With unstructured documents, it is highly recommended to put them through a process that gives them a common structure and converts the content into plain text, although we will later see that this method (RAG) seemed to me not as sensitive to format as previous methods (TF-IDF). If we decide to homogenize the documentation, we will need to review these issues:
- Identifying titles, authors, dates: Extract and structure important metadata from the documents.
- Thematic classification: Assign thematic tags or categories to the documents.
- Text format: Convert documents to a plain text format if they are in complex formats such as PDF, Word, HTML, etc.
- Character encoding: Ensure the text is in a uniform character encoding, such as UTF-8.
For the first approach, I will use the articles from the website, which are ultimately structured documents, but since they have elements that can confuse the model, I will transform them into a JSON file with a very simple structure (article title, source URL, and article content/text).
{
"title": ,
"url": ,
"content": {
"Chapter 1": [
],
"Chapter 2": [
],
.
.
.
}
}To transform the articles into a JSON file, I used the following code:
import requests
from bs4 import BeautifulSoup
import json
import re
def fetch_article(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract the article title
title = soup.find('h1', class_='entry-title').text.strip()
# Extract the article content
content_div = soup.find('div', class_='entry-content')
elements = content_div.find_all(['h2', 'p'])
# Organize content by chapters
article_content = {}
current_chapter = "Introduction" # Default chapter for any text before the first H2
article_content[current_chapter] = []
for element in elements:
if element.name == 'h2':
current_chapter = element.text.strip()
article_content[current_chapter] = []
elif element.name == 'p':
article_content[current_chapter].append(element.text.strip())
# Prepare the JSON structure
article_json = {
"title": title,
"url": url,
"content": article_content
}
return article_json
def extract_last_non_empty_word(url):
# Use a regular expression to find all the words between slashes
matches = re.findall(r'/([^/]*)', url)
# Filter out empty matches
non_empty_matches = [match for match in matches if match]
# Return the last non-empty word or None if there are no matches
return non_empty_matches[-1] if non_empty_matches else None
def save_article_to_json(article_json, file_path):
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(article_json, f, ensure_ascii=False, indent=4)
print(f"Article saved to {file_path}")
# Article URLs
urls = [
"https://arnaudunjo.com/ca/2024/07/07/creacio-dun-chatgpt-personalitzat-agent-gpt/",
"https://arnaudunjo.com/ca/2023/01/31/generant-codi-amb-gpt-3/",
"https://arnaudunjo.com/ca/2021/10/04/alarma-domestica-amb-raspberry-pi/",
"https://arnaudunjo.com/ca/2021/04/25/introduccio-al-machine-learning-aprenentatge-automatic/",
"https://arnaudunjo.com/ca/2021/04/25/machine-learning-model-classificador-de-textos-en-python/",
"https://arnaudunjo.com/ca/2021/02/11/millorant-la-seguretat-i-la-privacitat-en-les-comunicacions-amb-raspberry-pi/",
"https://arnaudunjo.com/ca/2021/01/13/opinio-moonlander-mk1/",
"https://arnaudunjo.com/ca/2020/12/17/desenvolupament-duna-aplicacio-blockchain-desde-0-amb-python/"
]
for url in urls:
last_word = extract_last_non_empty_word(url)
# Convert content to JSON
article_json = fetch_article(url)
# Save the JSON file
file_path = last_word + ".json"
save_article_to_json(article_json, file_path)
Of all the script, the complicated part is the function that parses the content and transforms it into the structure I mentioned (fetch_article). To summarize, it consists of invoking an HTML parser and separating the content by the three types of HTML tags that interest me:
- Texts in H1 tags are considered the title.
- Texts in H2 tags are considered chapters.
- Texts in P tags are considered the content of each chapter.
I apply this function to each of the articles and save the content in different files with a .json extension.
The generated files are saved with the structure mentioned earlier, for example:
{
"title": "Machine Learning: Text Classifier Model in Python",
"url": "https://arnaudunjo.com/ca/2021/04/25/machine-learning-model-classificador-de-textos-en-python/",
"content": {
"Introduction": [
"As I mentioned in the previous post, we are going to 'land' a practical example of how to implement a simple text classifier, specifically an incident classifier."
],
"Choosing a Language": [
"Returning to what I mentioned in the previous article, the most well-known languages for creating Machine learning projects are R, Python, and Java. I don't know R very well, but it seems less versatile than the other two. On the other hand, although Java is very well-known and robust, I have found more content on ML in Python and I also think it is more practical for taking the first steps (less structure to modify in each trial/error iteration) so we will choose this language to learn.",
"Additionally, there is the Jupyter Notebook project that allows you to program Python from a web interface, being able to execute the code by lines so you can execute only a part of the code as many times as you want but maintaining the states of the variables and objects with the values obtained from the previous lines without having to execute them again. It is very practical when working with operations that can take a long time to execute, as is the case with ML projects."
],
"The Data": [
"For our example, we will have a CSV file with more than 80,000 correctly categorized incidents.",
"We could also add the field that informs the person who wrote the incident as it can help us know what type of incident it is since a worker usually reports similar types of incidents. For example, a warehouse worker, due to the type of work they do, is more likely to report an incident to the maintenance department than to the accounting department.",
"So, the file will have the following structure:",
"As we talked about in the previous article, the quality of the data is very important. Given the source of the data, in this case, it was not necessary to clean it, but if the software saved the text in some kind of enriched format (for example HTML) before advancing and training the model, we would have polished the data.",
"After trying different algorithms (we will not go into the tests performed in this article), in our example, we will use the multi-class classification algorithm called 'Linear Support Vector Classification'."
],
"Getting into the Matter": [
"The first thing to do is read the training data, in this case, incidents.",
"As you can see, we need to install and import the Panda libraries, well-known among Python programmers. These will allow us to create a DataFrame (an object for manipulating data obtained from a structured data source) with the data read from the CSV file where we have all the incidents.",
"To avoid data inconsistencies, given incomplete data, we delete rows from the DataFrame that do not have all fields filled in.",
"To ensure the model considers the name of the person who created the incident, we will create a new field in the DataFrame where we join this person's name with the description text. This is the field we will work with from now on.",
"Since the computer only 'understands' numbers, we need to assign one to each category/queue. The model works with these identifiers and only when we want to display the results can we re-associate these identifiers with their corresponding descriptions.",
"To do this correctly, we need to use the DataFrame's factorize function, which will create a new column in the DataFrame with the number corresponding to the category to which the incident is assigned.",
"Before starting with algorithms, we will reduce the number of words the model will have to work with.",
"First, a lambda function to convert all uppercase letters to lowercase so that the same word with or without uppercase letters cannot be interpreted as two different words.",
"Then we will use the Spacy library to obtain the STOP_WORDS list corresponding to the language of the texts, in our case, Spanish. This list contains articles, frequent greetings, punctuation marks... words that we will remove from the text to optimize the model's training.",
"And now we come to one of the most important parts of training an ML model based on Natural Language (NL), the transformation of words into number vectors. In this case, the best algorithm we have found is to do it based on the frequency with which these words appear in the text. For example, for text 1, we will have a vector where each word occupies a position in it, and the value of this position is a value between 0 and 1 that indicates the frequency with which it appears in this text.",
"Of the parameters we pass to the constructor, it is worth highlighting:",
"Finally, we prepare the names of the different categories where we want to fit our texts into associative vectors.",
"Now we have the data ready to train the model properly. To do this, we will use the most famous ML library in Python, Sklearn. For this example, we are interested in two things from this library:",
"All the library's algorithms have a 'fit' function to which we must pass the two training data vectors. Once the model is trained, we call the 'predict' function, which will test the model with the test group incidents. This will allow us to assess the effectiveness we have achieved with this classification algorithm and the configured parameters.",
"As you can see, these libraries make the task much easier as they incorporate many algorithms and standardize the code for using them."
],
"Model Evaluation": [
"Finally, we can see the result of all the previous work. First, we will obtain a list of the names of all the categories/topics in which the texts could be classified and then 'print' the metrics table corresponding to the results obtained.",
"We will obtain a table like this (I have hidden the real category names as I am using a private dataset).",
"At first glance, we will see two sections, the upper part where each category will have its specific metrics, and the lower part where we have the overall result. The meaning of the different columns is this.",
"Therefore, we can see that we have achieved a general accuracy of 73% in a very simple way.",
"If we look more closely, we will see that for some categories, we have very low efficiency. This may be due to different problems:",
"Note that we left the algorithm's parameters at their default values when training the model. Normally, default values offer the best average results, but if we wanted to go deeper and get better results, we would have to study what each of the algorithm's parameters does (in this case, the LinearSVC) and try to find the best combination of them. There are automatic methods that, through brute force, tell you the most optimal parameter combination, but I only recommend them for projects that go into production as finding a better combination requires a large amount of computational resources and time. To make an approximation, default parameters offer good results.",
"You can find the complete code in my GitHub repository."
],
"Conclusion": [
"As we have seen, large projects are not necessary to apply Machine Learning techniques; they can be very modest projects, but what we will need are many examples.",
"This was just a very simple example that practically does itself. You only need to prepare the data a little, 'concatenate' a couple of library functions, and see the results. Thanks to the libraries we installed, by changing very few instructions, we can try different algorithms and see which one offers the best results for our case.",
"It may be surprising that we did not need extensive statistical knowledge to set it up. This is because the libraries we used already incorporate the most useful algorithms and will surely cover a large part of possible use cases. However, if we wanted to 'play' with the data, compare algorithms, refine predictions, etc., we would have needed good statistical knowledge.",
"Lastly, if you want to see more practical examples, there is Kaggle, a website where companies and individuals can request help in real 'machine learning' projects, and the community can help them selflessly or for a fee (companies often reward individuals who have provided a solution to the problem). Normally, the code is shared publicly to be useful to the rest of the community, making it a very interesting source of knowledge.",
""
]
}
}Okay, now we have the data in a JSON file, we can move on to indexing them.
Document Indexing
With the GPT API
In Python, we will use the llama-index library, which will do all the work, from reading the document contents to returning the model’s response.
Structured Files
As you will see, it is an extremely simple process (two lines of code), but at the same time very opaque, as you only have a very general idea of what it does.
import os
import openai
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
from llama_index.core.llms import LLM
from llama_index.llms.openai import OpenAI
import textwrap
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
os.environ["OPENAI_API_KEY"] = "WRITE YOUR GPT API KEY HERE"
# Define the path of the folder you want to check
directory_path = "./storage"
# Use os.path.exists() to check if the path exists
if os.path.exists(directory_path):
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir=directory_path)
# load index
index = load_index_from_storage(storage_context)
else:
# build the index
documents = SimpleDirectoryReader("documents").load_data()
# load it into memory
index = VectorStoreIndex.from_documents(documents)
# write it to disk so it doesn't have to be recreated from scratch every time
index.storage_context.persist()
# create a query engine based on the vectorized documentation
query_engine = index.as_query_engine()
context = "Always respond in Catalan."
question = "What was the overall efficiency of the Machine Learning algorithm I developed?"
prompt = context + question
response = query_engine.query(prompt)
print(response)Basically, if the index does not exist on the hard drive, I build it, load it into memory, and save it to the hard drive so it doesn’t have to be recreated each time. If the index already exists, I simply load it into memory. Then you just need to get the object that allows you to “ask” the documents and pass the “prompt”.
As there are few documents and they are relatively short, creating the index did not take even 4 seconds. Simply loading it into memory took about 1 second. If we load 6 documents in PDFs of about 150 pages, it takes about 50 seconds to vectorize and load them into memory and 16 seconds if it only has to read the index from the hard drive and load it into memory.
If you notice, this process is so opaque that you wouldn’t even know it is sending document information as context to the model; it’s almost magic. In fact, since we are using the default parameters, we don’t even know which model we are using (GPT 3.5, GPT 4…). This, in particular, is very simple, you just need to add two lines, but you still don’t have visibility into what it is doing.
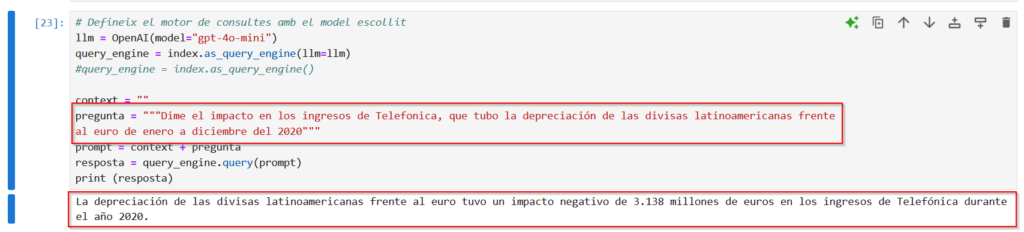
# Define the query engine with the chosen model llm = OpenAI(model="gpt-4o-mini") query_engine = index.as_query_engine(llm=llm) context = "Always respond in Catalan." question = "What was the overall efficiency of the Machine Learning algorithm I developed?" prompt = context + question response = query_engine.query(prompt) print(response)


Unstructured Files
Let’s get a little closer to a real use case, where many documents are unstructured (you know, Word, PDF…). As I mentioned, I downloaded Telefónica’s results presentations (from 2020 to 2024), which, being a company listed on the Spanish Stock Exchange, are public domain.


We look for a question to ask the model and find this piece in the 2020 results presentation


And basically that’s it, the libraries take care of all the magic. It doesn’t matter what type of file it has to read.

With Open Source Models
The truth is, I did similar tests about a year ago, and it was much more complicated, and the process couldn’t handle long documents (on my computer). With the new libraries that have emerged, it is much easier and more powerful.
The biggest difficulty is that large models need more computational resources than my desktop computer has, so I had to find a way to do the proof of concept without having to set up a lot of infrastructure. The fastest option was to use public “spaces” from Hugging Face.
For those who don’t know Hugging Face, it is a portal with a huge community dedicated to Machine Learning and AI models. There you can test the latest models that have come out, compare them, measure their performance, etc.
In this case, we will take advantage of the agreements they have with different providers who lend infrastructure (virtual machines) in the cloud to test the models. For example, thanks to the agreement between Hugging Face and Gradio, we can have a modest machine (2vCPU and 16GB of RAM) completely free to test. Each of these virtual machines (they are really Docker containers) and their configuration is what forms a “space”. Each Hugging Face user account can have infinite(?) “spaces”, and each of them can have an AI model running.
Since we are practical people, we will look for a space that contains the model we would like to test (in this case, the LLama 3.1 8B model).

Once inside, a chat interface will appear (a large window where you can see the conversation history) and a text input field at the bottom to enter the “prompt”. We can “play” with this chat, but what we really want is to test it in combination with the vectorization of our documents.
We can also clone the space we like to our account and thus have total control and configure it or add functionalities. In fact, from the model profile page itself, you can deploy a virtual machine in some of the most well-known cloud infrastructure providers. We just need to go to the models section, find the one we want, and click on “Deploy”.

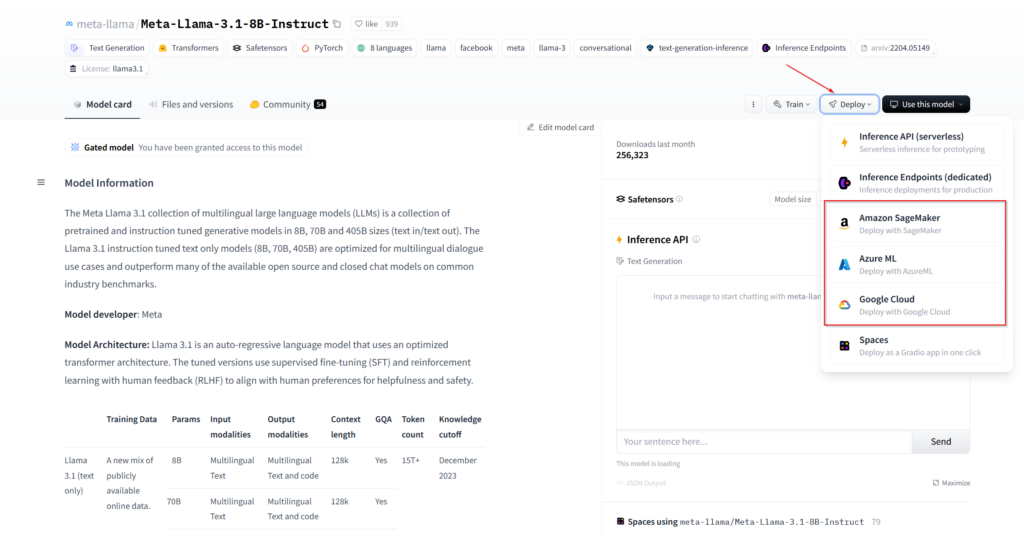
Structured Files
In any case, once we have a machine running the model, the steps to follow are the same. We will create a small script that we will run from a machine that has access to the documents, which will vectorize the documents and search the text in these documents related to the question we are asking. Then we will take this text (the context) and attach it to our question so that the AI model will answer our question based on the context text we provided.
import os
import json
import requests
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.docstore.document import Document
from gradio_client import Client
# Define your Hugging Face API key
api_key = "write your Hugging Face token here"
# Load documents from a JSON files directory
def load_json_documents(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".json"):
with open(os.path.join(directory_path, filename), 'r', encoding='utf-8') as file:
content = json.load(file)
text = ""
for section in content.get('content', {}).values():
if isinstance(section, list):
text += "\n".join(section)
else:
text += section
documents.append(Document(page_content=text, metadata={"title": content.get("title"), "url": content.get("url")}))
return documents
# Vectorize the documents
def vectorize_documents(documents):
embeddings = HuggingFaceEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
return vectorstore
# Create a prompt based on the vectors and the question
def create_prompt_from_vectors(vectorstore, question):
docs = vectorstore.similarity_search(question, k=5)
combined_docs = "\n".join([doc.page_content for doc in docs])
prompt = f"{combined_docs}\n\nQuestion: {question}\nAnswer:"
return prompt
# Path to your JSON documents directory
document_directory = "C:\\Users\\Naudor\\prova_chatgpt\\documents"
# Load and vectorize the documents
documents = load_json_documents(document_directory)
vectorstore = vectorize_documents(documents)
# Question you want to ask
question = "What is the overall efficiency of the machine learning model I developed?"
question = "What is my opinion on Moonlander MK1?"
# Generate the prompt from the vectors and send the request to the API
prompt = create_prompt_from_vectors(vectorstore, question)
client = Client("vilarin/Llama-3.1-8B-Instruct")
result = client.predict(
message=prompt,
system_prompt="Always answer in Catalan. You are answering based on articles I have written",
temperature=0.8,
max_new_tokens=4096,
top_p=1,
top_k=20,
penalty=1.2,
api_name="/chat"
)
print(result)If you notice, here we can better follow the steps it takes.
We still have a function that reads the files (load_json_documents). Then we have “vectorize_documents” which vectorizes the documents and creates the index. Here we should pay attention to the first line where it creates an object we had not seen until now, the “embeddings”. For now, we will say that it is a vector representation of one or more words/phrases, and later we will delve a little more into how documents are vectorized and what “embeddings” are.
A little further down, we see the function “create_prompt_from_vectors” which, starting from the question we want to ask, searches all the documents for up to 5 pieces of text that it deems relevant to the question. Then it returns the “prompt” which is the concatenation of these pieces plus the question we are actually asking.
Finally, we create a Client object and initialize it to fetch the model in the chosen space and print the model’s response.

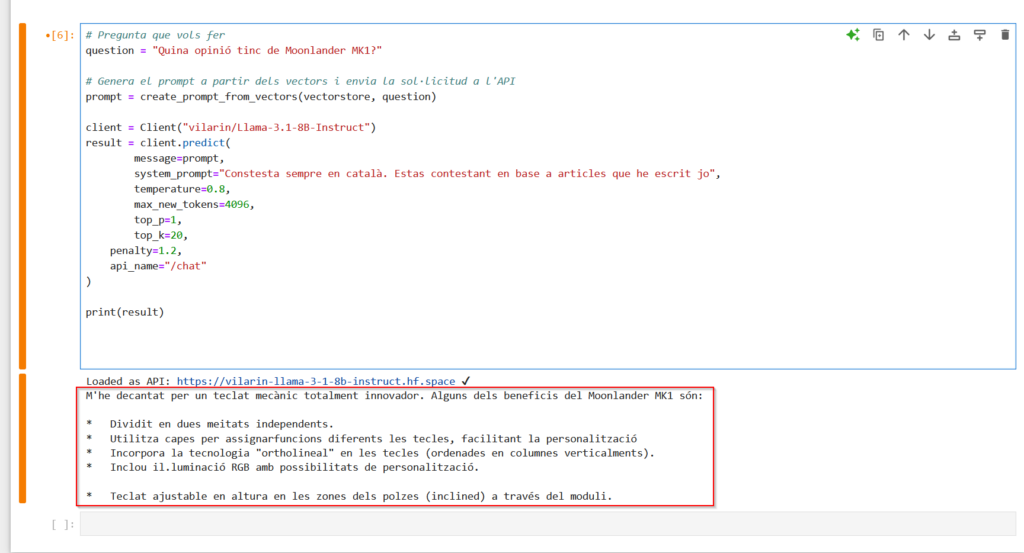
Unstructured Files
Since they are unstructured documents, you should think and test for each type of document what “chunk” partition strategy is most convenient, but it should be noted that the simplest and most widely usable strategy for unstructured documents is to divide them by pages, which works quite well.
So we will have to make some modifications to the code that vectorizes the documents.
# Load the PDF documents
def load_pdf_documents(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".pdf"):
file_path = os.path.join(directory_path, filename)
pages_text = extract_text_from_pdf(file_path)
for i, page_text in enumerate(pages_text):
documents.append(Document(page_content=page_text, metadata={"title": filename, "page_number": i + 1}))
return documents
# Extract text from each page of a PDF file
def extract_text_from_pdf(file_path):
doc = fitz.open(file_path)
pages_text = [doc.load_page(page_num).get_text() for page_num in range(len(doc))]
return pages_textWe will repeat the question we asked using GPT models, and we see that the algorithm has correctly found the “chunk” where the information the model needs to answer us is located.

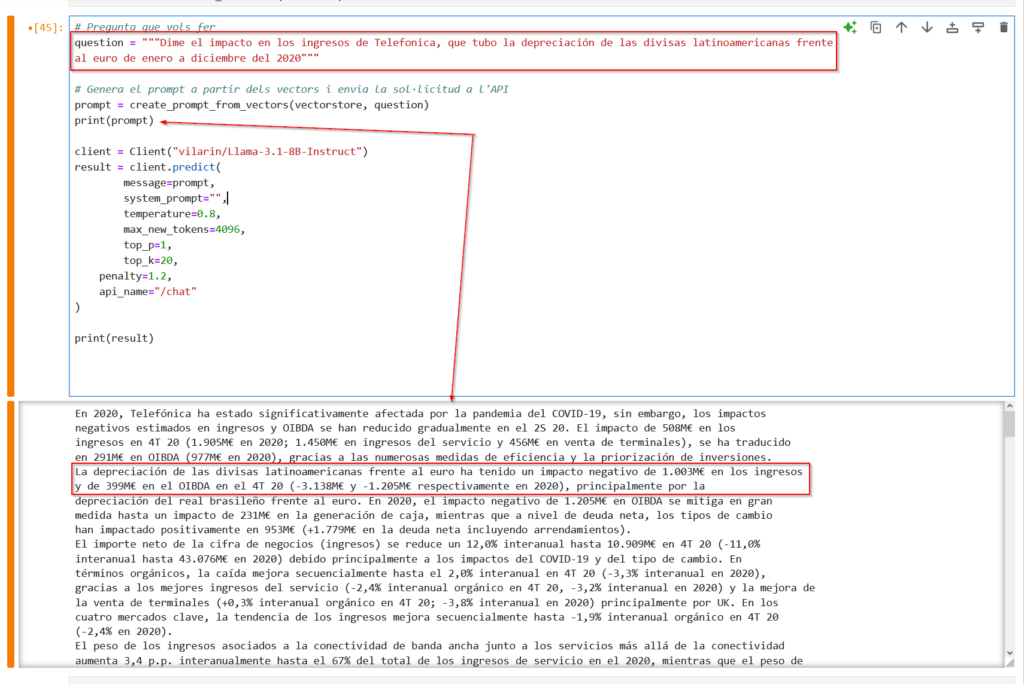
With all this context, the model responds as follows:

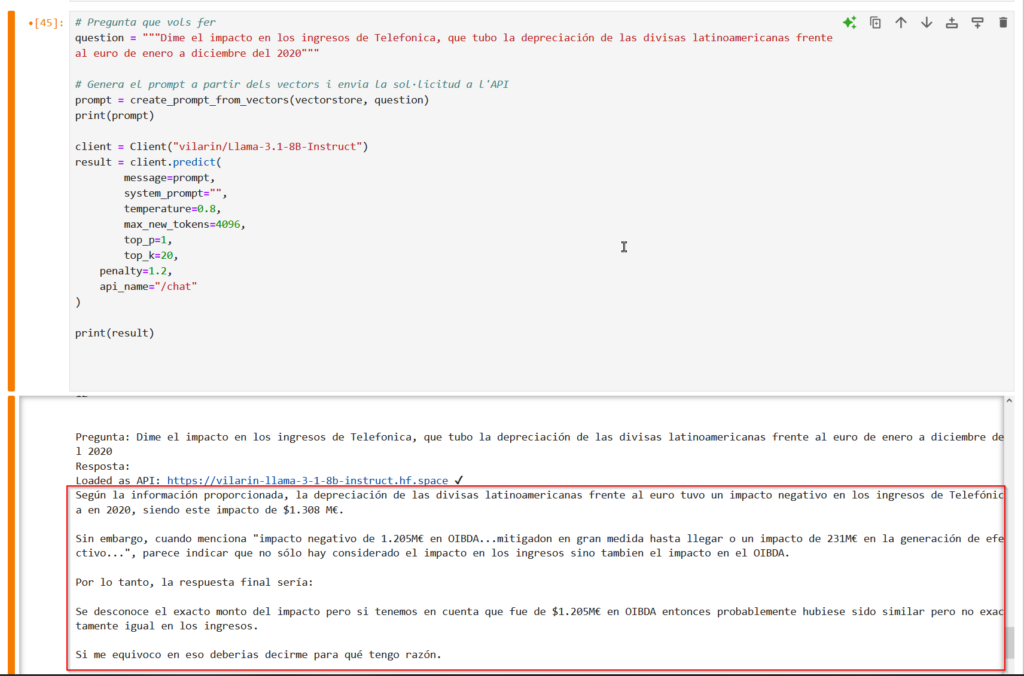
You can download all the code from my repository.
Document Vectorization Process
As we have seen during the tests, you first need to have the document contents vectorized in which you want to search. To do this, the content is first extracted from the file and separated into semantically significant chunks.
Each of these chunks must be converted into “embeddings,” which are nothing more than vector representations of objects in a multidimensional space (vectors of many dimensions) and serve to transform data into a format that algorithms can use. This process is done to facilitate the search as much as possible because if we delve into the deeper levels of how computers work, in the end, the only thing they know how to work with is numbers. Whether you are writing a novel, editing an image, or watching a video, in the end, computers work with numerical representations of what appears on the screen.
In the image example, we see that we have different words (cat, kitten, dog…) and each of them is represented by a vector. Each cell in the vector is a feature, and the value in the cell indicates “how true” that feature is for that word (a score of 1 means that word fully satisfies that feature, and a score of -1 means that word is impossible to satisfy that feature).

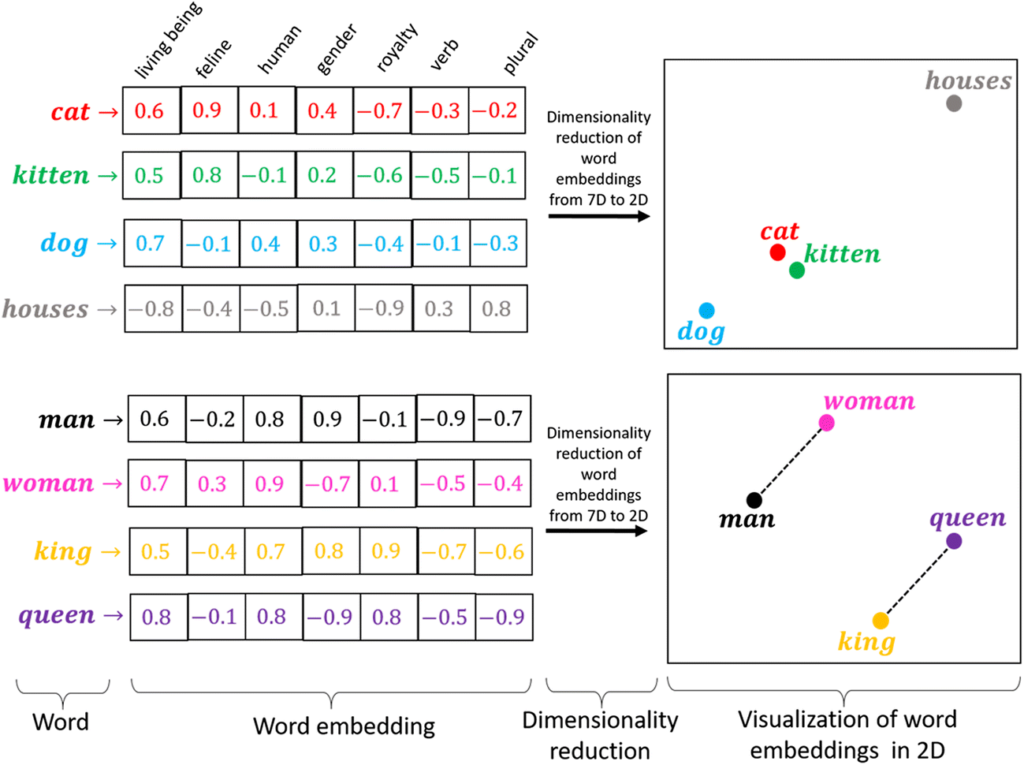
For example, a “cat” has a higher score than a “kitten” in terms of the feature of being a feline, but a “kitten” has a much higher score than a “dog” or a “house”. Considering all the features, we get a representation like the graph on the right, where a “cat” and a “kitten” are very close, and a “dog,” while farther from the first two words, is closer to them than the word “houses,” which has no relation to the other words.
In the second graph, we see that the distance between “man” and “woman” is the same as between “king” and “queen,” as the only notable difference between “man” and “woman” is the same as between “king” and “queen,” the gender.
Thus, if my “prompt” contained the word “cat,” the “chunks” containing the word “kitten” will be considered more relevant than the “chunks” containing the word “houses”.
This whole process is called RAG (Retrieval-Augmented Generation) and has been used at least since the appearance of chat GPT 3.5 to avoid the limitations of AI models, such as:
- Access to updated information.
- Answers that are too generic or out of context.
- Avoiding constant fine-tuning.
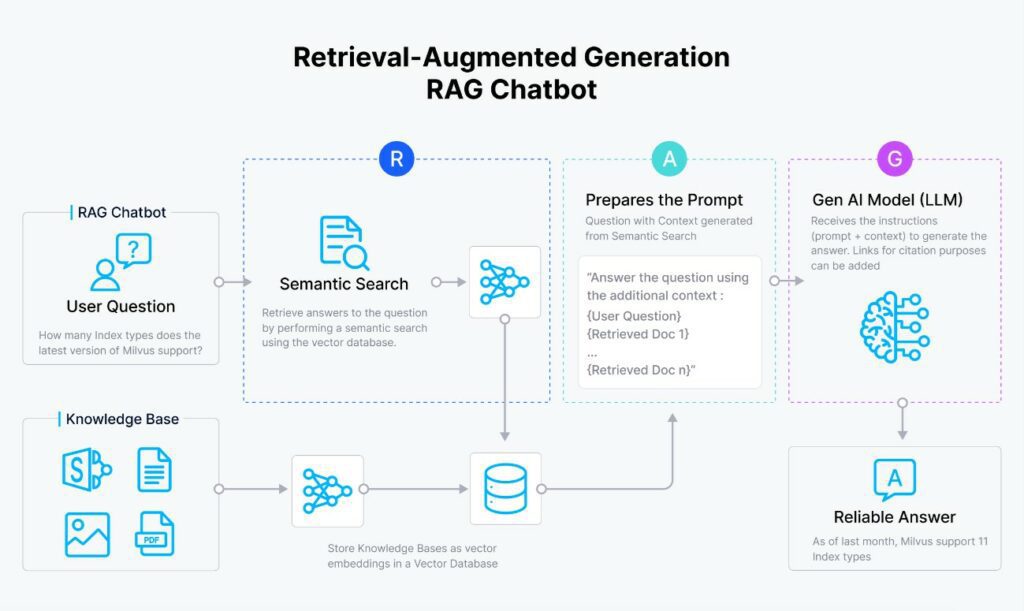
As seen in the following diagram, RAG consists of the following steps:
- The user’s question is vectorized.
- The question vector is compared with all the vectors in the index (typically a database with the “embeddings” of each “chunk”).
- The N most similar vectors are taken, and the original texts of these are retrieved.
- The “prompt” is formed with the context (the texts from the previous step) plus the user’s question.
- The “prompt” is sent to the AI model, and it returns the answer.

Conclusion
As I mentioned, these are simple examples and methods since, given the number of documents, type, and length, it is not worth setting up infrastructure specifically. If we had to set up such an application in a business environment, we would have to address at least the following issues:
- Distributed computing: We will have many documents, so we will have to think about distributed platforms (many machines working in parallel on the same process, even in the same stage of the process). The most well-known platforms are Amazon EMR, Microsoft Azure HDInsight, Databricks, and Hortonworks Data Platform.
- Document quantity and formats: Most documents will not be structured (Words, PDFs…). We will need to find the best way to “polish” and “cut” each type of document.
- Storage and access: Where will we store all the information (both raw and once vectorized)? There are database systems designed specifically for these uses. The most popular systems are Amazon Redshift, Google BigQuery, Cloudera Data Platform, Databricks Lakehouse, and Snowflake.
- Optimization of the platform to avoid skyrocketing exploitation costs.
- Privacy: A bit related to points 1 and 2 on this list, as if we don’t want to have it as an external service, we will be constantly exposing our documentation. Therefore, if we want to maximize/prioritize this point, it will always be better to rely on platforms that can be hosted on our own infrastructure and open source.
- Integration with the rest of the business applications with RAG.
I hope you found the article interesting.