

Introduction
Since after the summer holidays, I have been implementing chatbots based on LLMs (Large Language Models) in SMEs professionally. I’ve just started, so for now, they are quite simple (they respond with company information, book appointments, find information in corporate documentation…), but it’s a starting point. The fact is that it hasn’t taken long to see that current models, even though they do much more than we expected just over two years ago, are very, very far from being intelligent.
It was an “open secret” because if you look at the benchmarks performed on the models, they are quite good at some tasks but far from being efficient enough at others, especially when reasoning is required.
Considering how they work internally (placing the most probable words one after another), it makes sense that they excel at anything predictable or that they can extrapolate with many examples. However, this doesn’t hold for logical problems.
Even so, they are and will be a revolution, possibly wilder than the steam engine. Right now, for most uses, we don’t need an agent that knows how to reason but rather one that knows the answer to questions you would traditionally search for on the Internet. So much so that, having access to ChatGPT o1, even though it seems very limited and appears to “reason,” I only use it for programming tasks, while for everything else, I use the “normal” (ChatGPT 4o). At this point, those of us who use LLMs regularly typically use them as tools to save a lot of time asking questions we used to search for on the Internet, but (I believe I speak for the majority) we are not expecting them to reason. It would be fantastic if they did, but the improvement over what we had two years ago is so significant that we are still digesting it. Therefore, we already have plenty to work on exploiting them without this capability. In fact, many people have never used ChatGPT, and although more people use it every day, far fewer decide to invest €20 to unlock its full potential.
Limitations Found
While implementing the chatbots mentioned earlier, some cases have emerged that, for a person, are very basic to understand, but no matter how much I tried to explain them to an LLM, it could not handle them correctly:
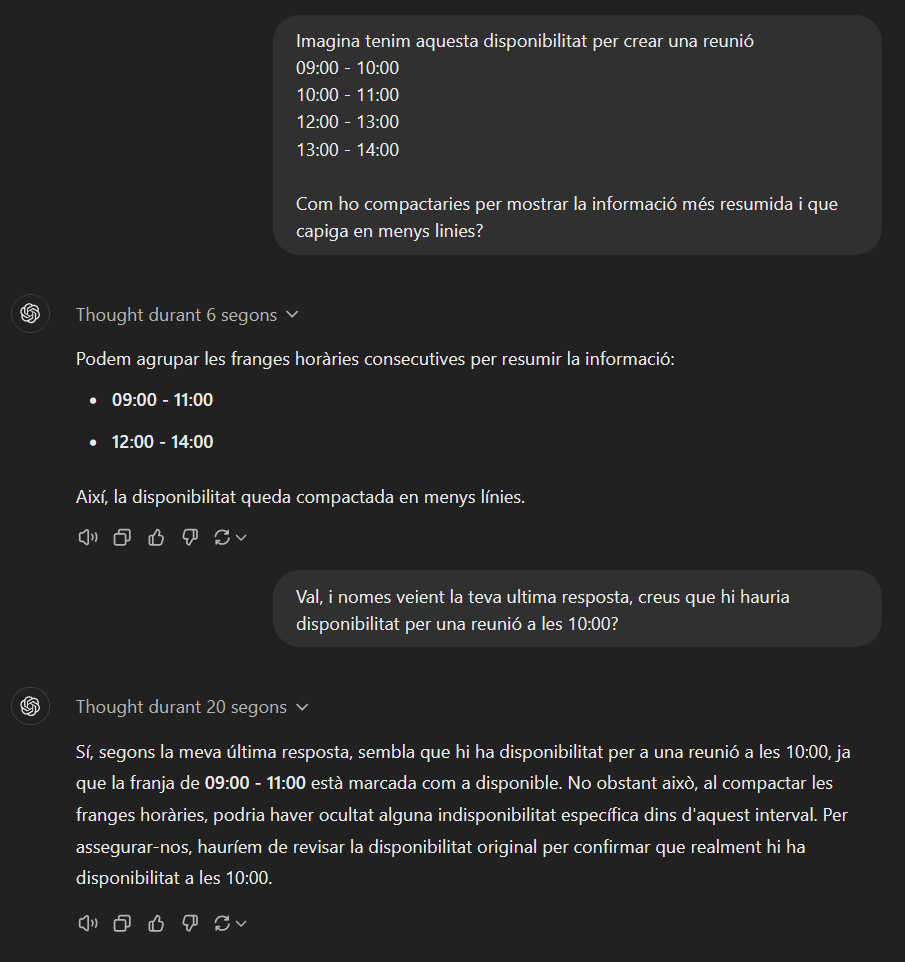
Availability compacting: One of the requested functions was for the chatbots to be able to book an appointment. Initially, the information the chatbot received was the different time slots available for scheduling an appointment, for example: Date 11/28/2024, 09:00 – 10:00, 10:00 – 11:00, 11:00 – 12:00…
If presented this way, it was very repetitive and impractical to read on a small mobile screen (WhatsApp). So I thought of giving instructions to compact the time intervals with availability. In the previous case, it would look something like this: Date 11/28/2024, from 9:00 to 12:00.
With a few brief explanations, a 7-8-year-old child could do it without much trouble.
Unfortunately, the LLMs weren’t as intelligent as a 7-8-year-old child. Despite explaining it in various ways, using “prompt engineering” techniques, providing two examples, etc., I lost my patience and eventually modified the function that returned the availability to the LLM so that it would already return the job done. Perhaps there is some magic formula to achieve this, but I couldn’t find it no matter how many explanations I provided.
Selecting a time within an interval: Slightly related to the previous issue, once the availability was compacted, there was no way for it to realize that it was valid for a user to schedule an appointment at a time within the availability interval. For example, if the availability interval was from 9:00 to 13:00 and the user requested an appointment at 10:00, it would respond that there was no availability at that time, only at 9:00 or 13:00. As with the previous example, I tried explaining it in a thousand ways, with examples, etc., but I had to implement another function to indicate whether the time proposed by the user was viable or not, as the model itself did not know.
The New ChatGPT o1 Model
In the chatbots, I am using the ChatGPT 4o mini model, which is fast and economical but with enough fluency to follow simple instructions and provide a good experience.
However, as mentioned earlier, AI evolves very rapidly, and this problem has been solved with new models, such as ChatGPT o1, which is currently available only as a “beta.”
Unfortunately, at the time of this post’s publication, this model has not yet been fully released, and when it is, it will be considerably more expensive than the 4o mini. For now, the chatbots will continue using the old model.
How ChatGPT o1 Works
This new “model,” currently in beta, iterates multiple times over its response, modifying it if it realizes it is incorrect. I’ve put “model” in quotes because it hasn’t been trained from scratch but rather fine-tuned on ChatGPT-4o to incorporate “prompt engineering” techniques like the famous “Chain of thought” in its answers, making it capable of providing much more reliable solutions on more complex topics. Additionally, it provides a much more detailed explanation about what and why it answered as it did. Sometimes, such detail isn’t necessary, but if you want to understand its reasoning or learn to do it yourself, it’s incredibly useful.
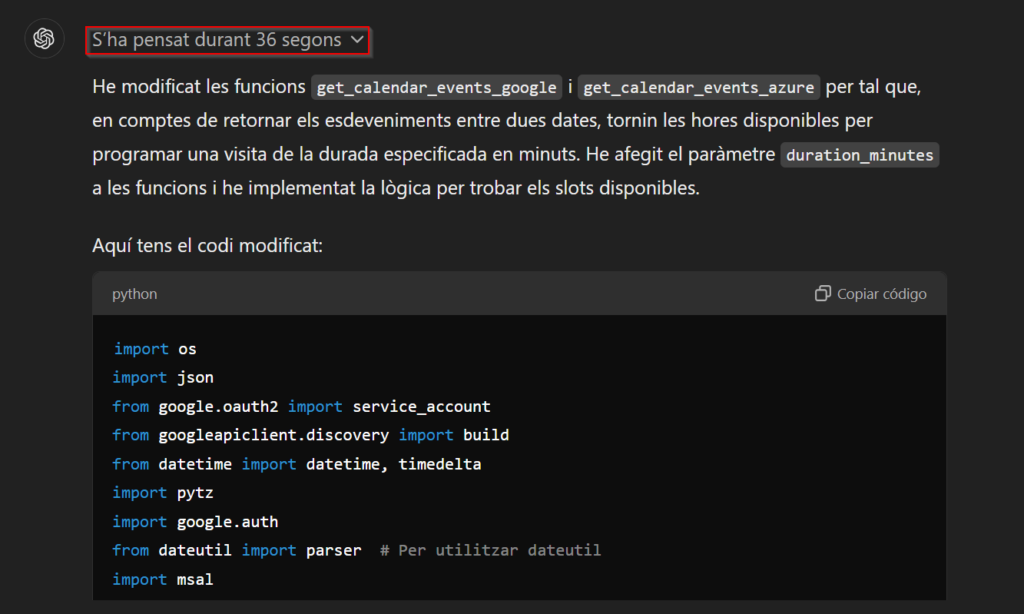
As seen in the image, this model is much slower than we are used to because it checks its response to ensure it is error-free and coherent, iterating on it. This also makes responses much more costly.
I use it a lot for programming, and one advantage is that it naturally includes many of the most common error-handling routines and comments the code extensively. These are tasks easy to overlook, and it’s a relief to have them taken care of. In fact, even if you don’t have access to the new model, for a few months now, you can inform the “older” models about things they should consider when responding. For example, you can tell them always to follow certain guidelines when generating code, and they will remember them across different sessions (I believe this option is only available for Plus users).
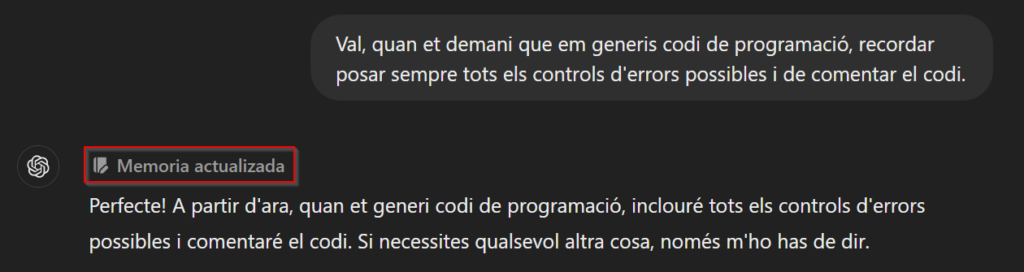
Obviously, it still requires human supervision, but avoiding the “silly” errors of the past and having the model “think” a bit makes it useful for all kinds of tasks.
In fact, it performs well in some specific programming benchmarks:
– APPS (Automated Programming Progress Standard): around 40-50% accuracy in easy problems and 15-20% in difficult problems.
– MBPP (Mostly Basic Python Problems): nearly 80% performance in basic problems.
– LeetCode: over 90% accuracy in easy problems, while medium-level ones range between 50-60%.
These percentages might not seem very high, especially for difficult problems, but the vast majority, if not all, of the algorithms created by a “standard” programmer are easy or medium-level. Difficult ones are only needed for scientific/clinical programs or those requiring very high performance. Therefore, we’re talking about a tool that can do half the work for you, and coming from a generalist model with just two generations, I think that’s quite remarkable.
Obviously, the more specific you are when assigning tasks, the better the results. It still doesn’t perform the “magic” of letting any user create a complete application without a programmer’s guidance, but undoubtedly, programmers will now be much more efficient and able to tackle far greater challenges with this model’s assistance.
Conclusions
Rumors suggest that AI researchers are hitting the scalability limits of current models. It’s becoming extremely difficult to find more information to train the models, and some are trying to generate synthetic information (created by other AI models). However, the underlying issue is that no matter how much data they add to training, the models no longer improve significantly as they have in the past. Therefore, while finding a way to overcome this barrier or designing a better standard mechanism than predicting the next word, older models can still be improved by applying optimization techniques:
- Chain of thought.
- Allowing Internet searches.
- Multi-agent systems.
- Multimodal optimization.
- Specialized models.
- Self-learning?
- …
As mentioned, we are far from achieving AGI (Artificial General Intelligence). However, by combining both types of models (one faster but less precise and another slower but more accurate) along with all the techniques that can be applied in inference layers, there’s room for improvement without waiting for a paradigm shift in frontier models.