

Introducció
Des de després de les vacances d’estiu, estic implementant xatbots basats en LLM’s (Large Language Models) a PIMES de forma professional. Acabo de començar, per tant, de moment són força senzills (responen amb informació de l’empresa, reserven cites, troben informació en la documentació empresarial…) però és un punt de partida. El cas és que no ha calgut gaire per començar a veure que els models actuals, tot i fer molt més del que esperàvem fa poc més de dos anys, estan molt, però que molt lluny de ser intel·ligents.
Era un secret “a veus”, ja que si mires els benchmarks que es fan als models, en algunes tasques són força bons, però en d’altres estan lluny de ser prou eficients, especialment si han de raonar.
Si pensem en com funcionen internament (col·locant les paraules més probables una darrere l’altra), té sentit que siguin bons en tot allò que sigui predictible o que puguin extrapolar tenint molts exemples, però amb problemes de lògica això no succeeix.
Tot i això, són i seran una revolució, possiblement més salvatge que la màquina de vapor. Ara mateix, per la major part dels usos no necessitem un agent que sàpiga raonar, sinó simplement que sàpiga la resposta a preguntes que tradicionalment buscaries a Internet. Tant és així que, tenint accés a ChatGPT o1, tot i que de forma molt limitada sembla que “enraoni”, només el faig servir per tasques de programació, però per tota la resta faig servir el “normal” (ChatGPT 4o). A hores d’ara, la gent que fem servir els LLM de forma habitual, normalment els fem servir com una eina que ens estalvia molt de temps fent preguntes que abans fèiem a Internet però (crec que parlo per la resta) no estem esperant que enraonin. Seria fantàstic que ho fessin, però la millora respecte al que teníem fa dos anys és tan gran que encara ho estem digerint. Per tant, ja tenim prou feina intentant explotar-los sense aquesta habilitat. De fet, molta gent no ha fet servir mai ChatGPT i, tot i que cada dia en som més, molta menys decideix invertir 20 € per tenir-ne tota la potència.
Limitacions trobades
El cas és que, implementant els xatbots que us deia abans, han aparegut alguns casos que per a una persona, són molt elementals d’entendre, però que, per més que he intentat explicar-li a un model LLM, no ha sigut capaç de fer bé:
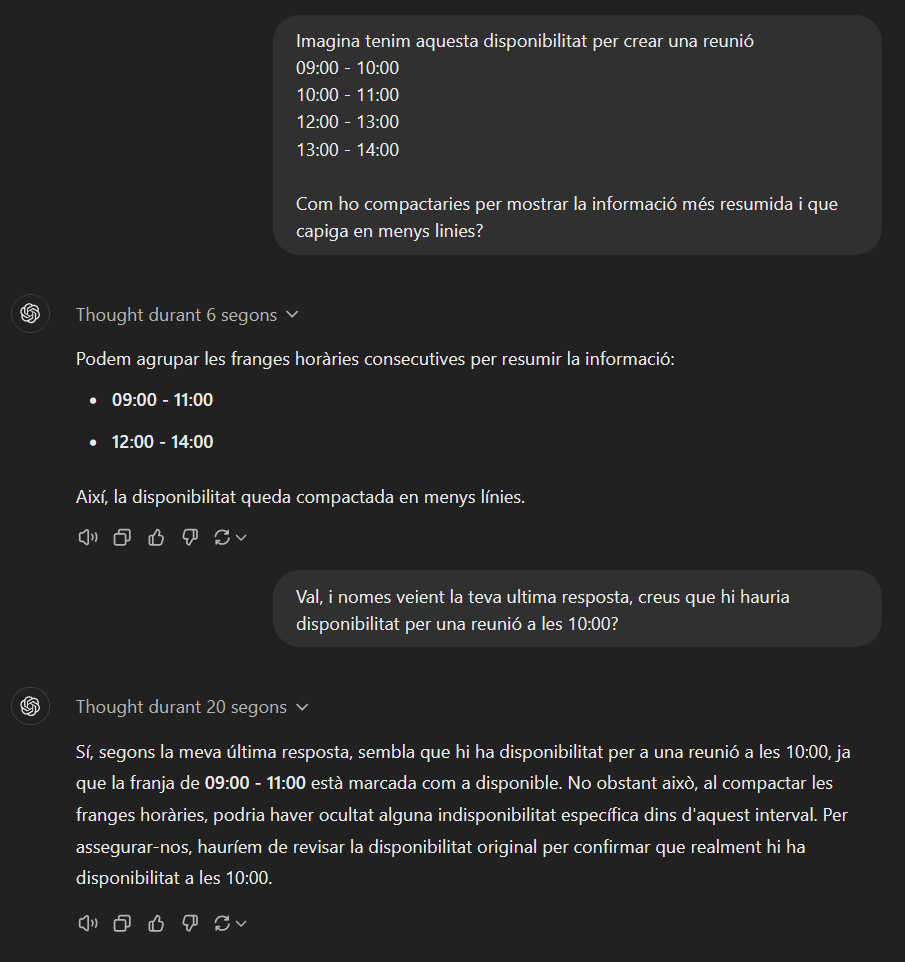
Compactació de disponibilitat: Una de les funcions que se m’ha demanat és que els xatbots puguin reservar una cita. Inicialment, la informació que rebia el xatbot eren les diferents franges en què hi havia disponibilitat per programar una cita, per exemple: Dia 28/11/2024, 09:00 – 10:00, 10:00 – 11:00, 11:00 – 12:00…
Si ho presentava així era molt repetitiu i poc pràctic de llegir en una pantalla petita de mòbil (WhatsApp). Així que vaig pensar en donar-li les instruccions de manera que compactés els intervals de temps en què hi havia disponibilitat. En el cas anterior, es quedaria quelcom semblant a això: Dia 28/11/2024, de 9:00 a 12:00.
Amb unes breus explicacions, un nen/nena de 7-8 anys t’ho faria bé sense gaires problemes.
Desgraciadament, els LLM’s no eren prou intel·ligents com un nen o nena de 7-8 anys. Tot i explicar-los-ho de diverses maneres, utilitzant tècniques de “prompt engineering”, posant-hi dos exemples, etc., vaig perdre la meva reserva de paciència i, finalment, vaig modificar la funció que li tornava al LLM la disponibilitat, de tal manera que ja li tornés amb la feina feta. Potser hi ha alguna fórmula màgica que ho aconsegueixi però jo no la vaig trobar per més explicacions que li facilités.
Escollir una hora dins d’un interval: Una mica relacionat amb l’assumpte anterior, un cop tenia la disponibilitat compactada, tampoc hi va haver manera que fos capaç d’adonar-se que era correcte que un usuari volgués programar una cita a una hora que estigués enmig de l’interval de disponibilitat. Per exemple, si teníem un interval de disponibilitat de 9:00 a 13:00 i l’usuari demanava la cita per les 10:00, et contestava que a aquella hora no hi havia disponibilitat, que només podia ser a les 9:00 o a les 13:00. Com en l’exemple anterior, vaig provar d’explicar-ho de mil maneres, amb exemples, etc., però vaig haver d’implementar una altra funció que indiqués al model si l’hora proposada per l’usuari era viable o no, ja que el model per si sol no ho sabia.
El nou model ChatGPT o1
En els xatbots estic fent servir el model ChatGPT 4o mini, que és ràpid i econòmic, però amb suficient soltesa per seguir instruccions senzilles i tenir una bona experiència.
Però, com us deia, la IA evoluciona molt ràpidament i aquest problema s’ha solucionat amb els nous models, com per exemple el ChatGPT o1, del qual ara per ara només hi ha disponible una “beta”.
Desgraciadament, a data de publicació d’aquest post, encara no s’ha alliberat completament aquest model, i quan ho facin, serà força més car que el 4o mini. Per tant, de moment els xatbots seguiran utilitzant el model antic.
Funcionament de ChatGPT o1
Aquest nou “model”, que ara mateix està en fase beta, itera diverses vegades sobre la seva resposta i la va modificant si s’adona que no és correcta. He posat “model” entre cometes ja que realment no s’ha entrenat un model des de zero, sinó que s’ha agafat el ChatGPT-4o i se li ha fet un “fine-tuning” per tal d’incloure tècniques de “prompt engineering” com la famosa “Chain of thought” a les seves respostes, de manera que és capaç de proporcionar solucions molt més fiables i sobre assumptes més complexos. A més a més, proporciona una explicació molt més detallada sobre el què i el per què de la resposta que t’ha donat. Algunes vegades no caldria tanta explicació, però si vols saber per què t’ha donat aquella resposta o vols aprendre a fer-ho tu mateix, és realment molt útil.
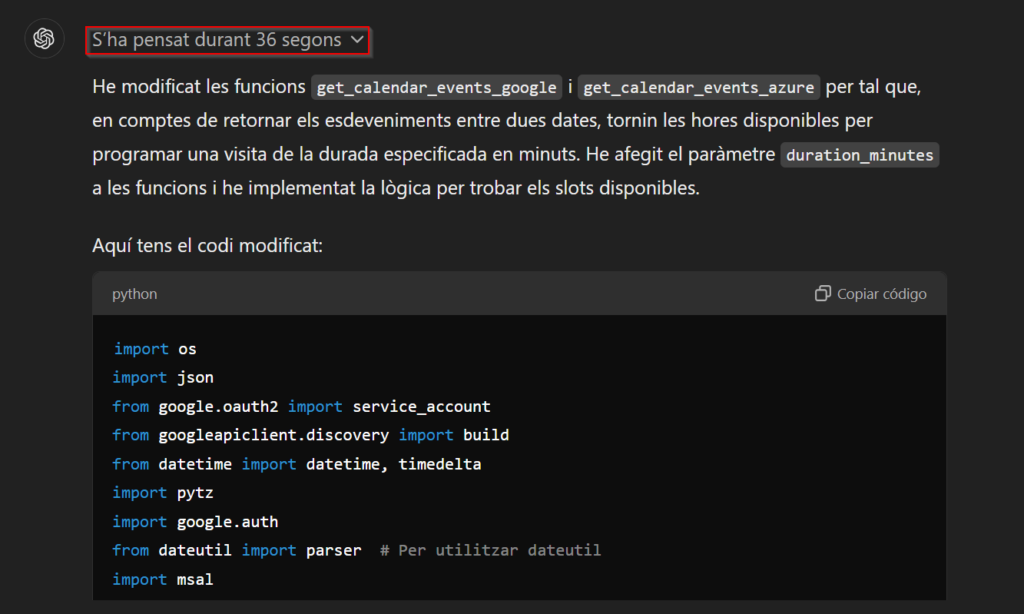
Com es veu a la imatge, aquest model és molt més lent del que estem acostumats, i això és degut al fet que comprova que la seva resposta no contingui errors i sigui coherent, iterant sobre ella. Això també provoca que les respostes siguin molt més costoses.
Jo el faig servir molt per programar i un dels avantatges és que, de forma natural, inclou molts dels tractaments d’errors més habituals i comenta molt el codi. Això són tasques fàcils d’oblidar i s’agraeixen que es facin. De fet, encara que no tingueu accés al nou model, des de fa uns mesos podeu informar els models “antics” de coses que han de tenir en compte a l’hora de contestar. Per exemple, se li pot dir que sempre que li demanis que et generi codi segueixi unes pautes, i ho tindrà en compte entre les diferents sessions que tingueu (aquesta opció crec que només està disponible per a usuaris Plus).
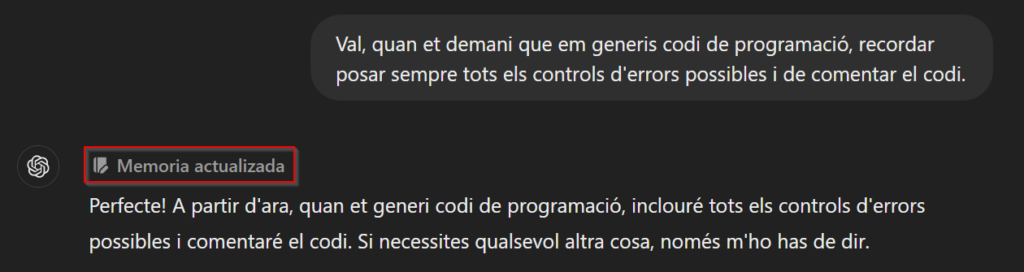
Òbviament, encara necessita la supervisió d’una persona, però el fet d’evitar els errors “tontos” d’abans i que el model “pensi” una mica fa que es pugui aprofitar en tota mena de tasques.
De fet, en alguns benchmarks específics de programació treu bones notes:
– APPS (Automated Programming Progress Standard): una precisió al voltant del 40-50% en els problemes de nivell fàcil i entre 15-20% en problemes de nivell difícil.
– MBPP (Mostly Basic Python Problems): un rendiment proper al 80% en problemes bàsics.
– LeetCode: la precisió en els problemes fàcils és superior al 90%, mentre que en els mitjans oscil·la entre 50-60%.
Aquests percentatges poden no semblar gaire alts, especialment en problemes difícils, però és que la gran majoria, per no dir tots, dels algoritmes que fa un programador “estàndard” són fàcils o mitjans. Els difícils només són necessaris per a programes científics/clínics o aquells que requereixen un rendiment molt bo. Per tant, estem parlant que aquest algoritmes et pot fer la meitat de la feina, i això, venint d’un model generalista i amb només dues generacions, crec que és prou destacable.
Òbviament, com més específic siguis donant-li la tasca, millors resultats tindràs. Per tant, encara no fa la “màgia” que un usuari qualsevol pugui fer una aplicació completa sense la guia d’un programador però, sens dubte, ara els programadors seràn molt més eficients i podràn enfrontar-se a reptes molt més grans amb l’ajuda d’aquest model.
Conclusions
Les males llengües diuen que els investigadors en IA s’estan trobant amb el final de l’escalabilitat dels models actuals. Els costa moltíssim trobar més informació amb la qual entrenar els models, i alguns estan provant de generar més informació de manera sintètica (generada per altres models d’IA). Però el problema de fons és que, per més informació que afegeixin als entrenaments, els models ja no milloren de manera significativa com ho havien fet fins ara. Per tant, mentre troben una manera de superar la barrera o dissenyar un mecanisme estàndard millor que el de predir la següent paraula, encara poden seguir millorant els models antics aplicant només tècniques d’optimització:
- Chain of thought.
- Permetent la cerca d’informació a Internet.
- Sistemes multi-agent.
- Optimització del multimodal.
- Models especialitzats.
- Autoaprenentatge?
- …
Tot i que com deia que estem molt lluny d’una AGI (Artifical Gerenal Inteligent) amb la combinació dels dos tipus de models (un més ràpid pero no tant precís i un altre mes lent pero més precís) més totes les tècniques que es poden aplicar en capes de inferència tenim marge de millora sense arribar al punt de tenir que esperar a un canvi de paradigma en els models de frontera.