

Introducción
Desde después de las vacaciones de verano, estoy implementando chatbots basados en LLM’s (Large Language Models) en PYMES de forma profesional. Acabo de empezar, por lo que, de momento, son bastante sencillos (responden con información de la empresa, reservan citas, encuentran información en la documentación empresarial…), pero es un punto de partida. El caso es que no ha hecho falta mucho para empezar a ver que los modelos actuales, aunque hacen mucho más de lo que esperábamos hace poco más de dos años, están muy, pero que muy lejos de ser inteligentes.
Era un secreto “a voces”, ya que si miras los benchmarks que se hacen a los modelos, en algunas tareas son bastante buenos, pero en otras están lejos de ser lo suficientemente eficientes, especialmente si tienen que razonar.
Si pensamos en cómo funcionan internamente (colocando las palabras más probables una detrás de otra), tiene sentido que sean buenos en todo aquello que sea predecible o que puedan extrapolar teniendo muchos ejemplos, pero con problemas de lógica esto no sucede.
A pesar de ello, son y serán una revolución, posiblemente más salvaje que la máquina de vapor. Ahora mismo, para la mayoría de los usos no necesitamos un agente que sepa razonar, sino simplemente que sepa la respuesta a preguntas que tradicionalmente buscarías en Internet. Tanto es así que, teniendo acceso a ChatGPT o1, aunque de forma muy limitada parece que “razone”, solo lo utilizo para tareas de programación, pero para todo lo demás utilizo el “normal” (ChatGPT 4o). A estas alturas, las personas que usamos los LLM de forma habitual, normalmente los utilizamos como una herramienta que nos ahorra mucho tiempo haciendo preguntas que antes hacíamos en Internet, pero (creo que hablo por el resto) no estamos esperando que razonen. Sería fantástico que lo hicieran, pero la mejora respecto a lo que teníamos hace dos años es tan grande que todavía lo estamos asimilando. Por tanto, ya tenemos bastante trabajo intentando explotarlos sin esta habilidad. De hecho, mucha gente nunca ha usado ChatGPT y, aunque cada día somos más, mucha menos gente decide invertir 20 € para tener toda su potencia.
Limitaciones encontradas
El caso es que, implementando los chatbots que mencionaba antes, han aparecido algunos casos que para una persona son muy elementales de entender, pero que, por más que he intentado explicárselo a un modelo LLM, no ha sido capaz de hacerlo bien:
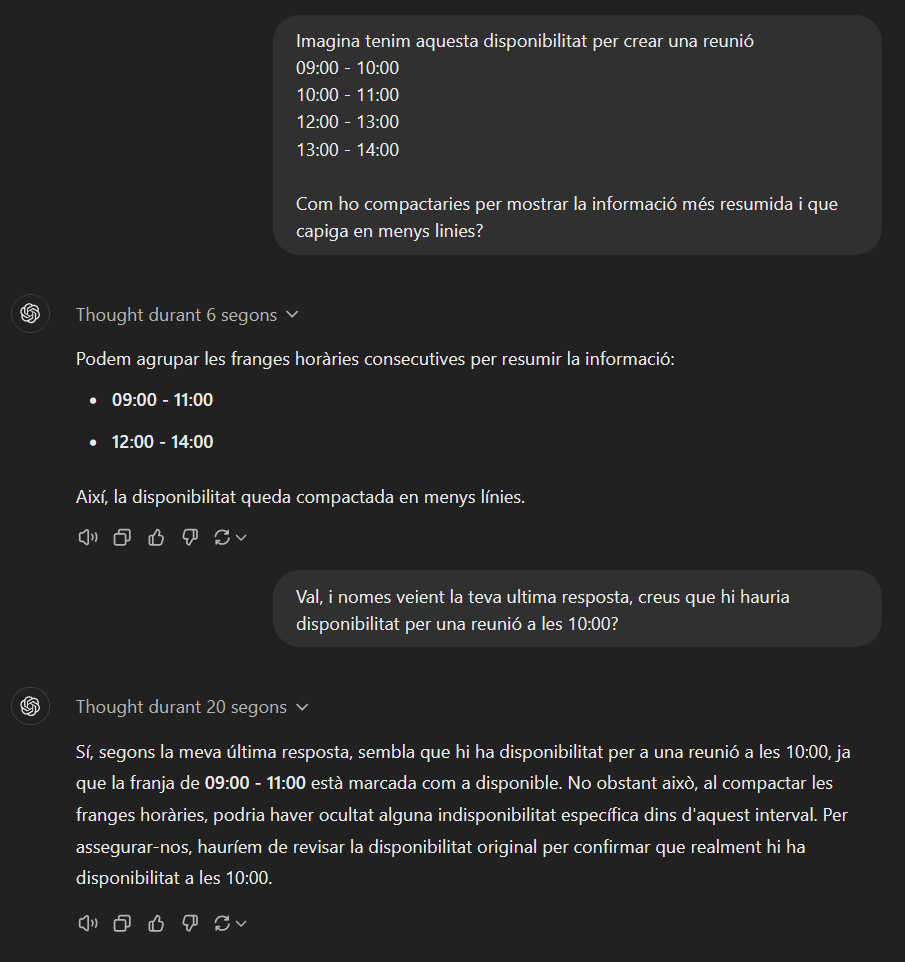
Compactación de disponibilidad: Una de las funciones que me pidieron fue que los chatbots pudieran reservar una cita. Inicialmente, la información que recibía el chatbot eran los diferentes intervalos en los que había disponibilidad para programar una cita, por ejemplo: Día 28/11/2024, 09:00 – 10:00, 10:00 – 11:00, 11:00 – 12:00…
Si lo presentaba así era muy repetitivo y poco práctico de leer en una pantalla pequeña de móvil (WhatsApp). Así que pensé en darle las instrucciones de manera que compactara los intervalos de tiempo en los que había disponibilidad. En el caso anterior, quedaría algo parecido a esto: Día 28/11/2024, de 9:00 a 12:00.
Con unas breves explicaciones, un niño/niña de 7-8 años lo haría bien sin muchos problemas.
Desgraciadamente, los LLM’s no eran lo suficientemente inteligentes como un niño o niña de 7-8 años. A pesar de explicárselo de varias maneras, utilizando técnicas de “prompt engineering”, poniéndole dos ejemplos, etc., perdí mi paciencia y, finalmente, modifiqué la función que devolvía al LLM la disponibilidad, de tal manera que ya le devolviera el trabajo hecho. Tal vez haya alguna fórmula mágica que lo consiga, pero yo no la encontré por más explicaciones que le facilitara.
Elegir una hora dentro de un intervalo: Algo relacionado con el asunto anterior, una vez tenía la disponibilidad compactada, tampoco hubo manera de que se diera cuenta de que era correcto que un usuario quisiera programar una cita a una hora que estuviera en medio del intervalo de disponibilidad. Por ejemplo, si teníamos un intervalo de disponibilidad de 9:00 a 13:00 y el usuario pedía la cita para las 10:00, respondía que a esa hora no había disponibilidad, que solo podía ser a las 9:00 o a las 13:00. Como en el ejemplo anterior, intenté explicárselo de mil maneras, con ejemplos, etc., pero tuve que implementar otra función que indicara al modelo si la hora propuesta por el usuario era viable o no, ya que el modelo por sí solo no lo sabía.
El nuevo modelo ChatGPT o1
En los chatbots estoy utilizando el modelo ChatGPT 4o mini, que es rápido y económico, pero con suficiente soltura para seguir instrucciones sencillas y ofrecer una buena experiencia.
Pero, como decía, la IA evoluciona muy rápidamente y este problema se ha solucionado con los nuevos modelos, como por ejemplo el ChatGPT o1, del cual por ahora solo hay disponible una “beta”.
Desgraciadamente, a la fecha de publicación de este post, aún no se ha liberado completamente este modelo, y cuando lo hagan, será bastante más caro que el 4o mini. Por lo tanto, de momento los chatbots seguirán utilizando el modelo antiguo.
Funcionamiento de ChatGPT o1
Este nuevo “modelo”, que ahora mismo está en fase beta, itera varias veces sobre su respuesta y la va modificando si se da cuenta de que no es correcta. He puesto “modelo” entre comillas ya que realmente no se ha entrenado un modelo desde cero, sino que se ha tomado el ChatGPT-4o y se le ha hecho un “fine-tuning” para incluir técnicas de “prompt engineering” como la famosa “Chain of thought” en sus respuestas, de modo que es capaz de proporcionar soluciones mucho más fiables y sobre temas más complejos. Además, proporciona una explicación mucho más detallada sobre el qué y el porqué de la respuesta que te ha dado. Algunas veces no haría falta tanta explicación, pero si quieres saber por qué te ha dado esa respuesta o quieres aprender a hacerlo tú mismo, es realmente muy útil.
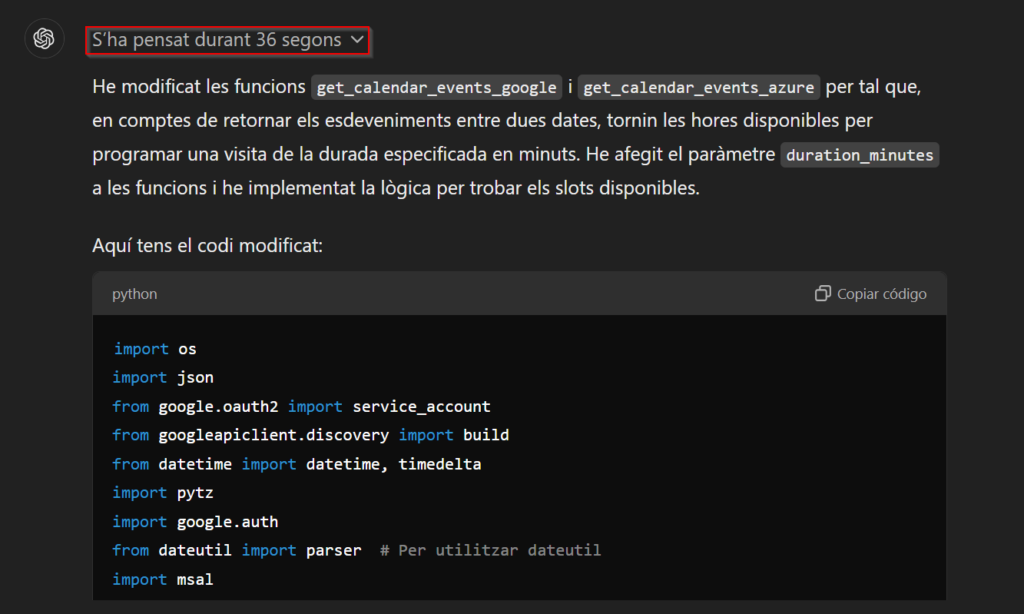
Como se observa en la imagen, este modelo es mucho más lento de lo que estamos acostumbrados, y esto se debe a que verifica que su respuesta no contenga errores y sea coherente, iterando sobre ella. Esto también provoca que las respuestas sean mucho más costosas.
Yo lo utilizo mucho para programar y una de las ventajas es que, de forma natural, incluye muchos de los tratamientos de errores más habituales y comenta mucho el código. Estas son tareas fáciles de olvidar y se agradece que se realicen. De hecho, aunque no tengáis acceso al nuevo modelo, desde hace unos meses podéis informar a los modelos “antiguos” de cosas que deben tener en cuenta al responder. Por ejemplo, se le puede decir que siempre que le pidas que te genere código siga unas pautas, y lo tendrá en cuenta entre las diferentes sesiones que tengáis (esta opción creo que solo está disponible para usuarios Plus).
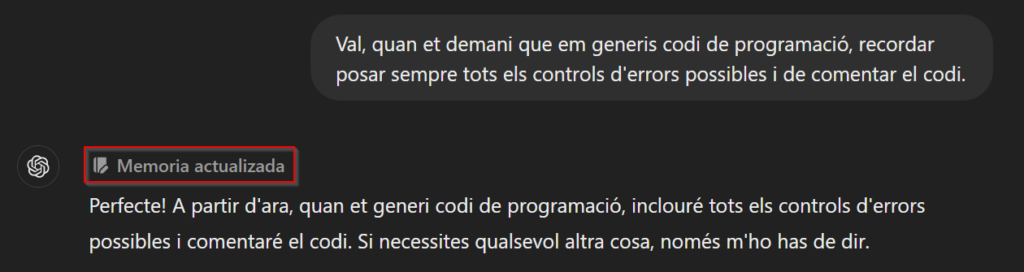
Obviamente, todavía necesita la supervisión de una persona, pero el hecho de evitar los errores “tontos” de antes y que el modelo “piense” un poco hace que se pueda aprovechar en todo tipo de tareas.
De hecho, en algunos benchmarks específicos de programación obtiene buenas puntuaciones:
– APPS (Automated Programming Progress Standard): una precisión alrededor del 40-50% en los problemas de nivel fácil y entre 15-20% en problemas de nivel difícil.
– MBPP (Mostly Basic Python Problems): un rendimiento cercano al 80% en problemas básicos.
– LeetCode: la precisión en los problemas fáciles es superior al 90%, mientras que en los medianos oscila entre el 50-60%.
Estos porcentajes pueden no parecer muy altos, especialmente en problemas difíciles, pero es que la gran mayoría, por no decir todos, de los algoritmos que hace un programador “estándar” son fáciles o medios. Los difíciles solo son necesarios para programas científicos/clínicos o aquellos que requieren un rendimiento muy bueno. Por lo tanto, estamos hablando de que estos algoritmos te pueden hacer la mitad del trabajo, y esto, viniendo de un modelo generalista y con solo dos generaciones, creo que es bastante destacable.
Obviamente, cuanto más específico seas dándole la tarea, mejores resultados obtendrás. Por lo tanto, todavía no hace la “magia” de que un usuario cualquiera pueda hacer una aplicación completa sin la guía de un programador, pero, sin duda, ahora los programadores serán mucho más eficientes y podrán enfrentarse a retos mucho más grandes con la ayuda de este modelo.
Conclusiones
Los rumores dicen que los investigadores en IA se están encontrando con el final de la escalabilidad de los modelos actuales. Les cuesta muchísimo encontrar más información con la que entrenar los modelos, y algunos están intentando generar más información de manera sintética (generada por otros modelos de IA). Pero el problema de fondo es que, por más información que añadan a los entrenamientos, los modelos ya no mejoran de manera significativa como lo habían hecho hasta ahora. Por lo tanto, mientras encuentran una manera de superar la barrera o diseñar un mecanismo estándar mejor que el de predecir la siguiente palabra, aún pueden seguir mejorando los modelos antiguos aplicando solo técnicas de optimización:
- Chain of thought.
- Permitir la búsqueda de información en Internet.
- Sistemas multi-agente.
- Optimización del multimodal.
- Modelos especializados.
- ¿Autoaprendizaje?
- …
Como decía, estamos muy lejos de una AGI (Artificial General Intelligence). Sin embargo, con la combinación de los dos tipos de modelos (uno más rápido pero no tan preciso y otro más lento pero más preciso) más todas las técnicas que se pueden aplicar en capas de inferencia, tenemos margen de mejora sin llegar al punto de tener que esperar un cambio de paradigma en los modelos de frontera.