



Recentment m’he introduït en el meravellós món del “machine learning”. Uns cursos de Linkeding Learning i unes hores de dedicació han estat suficients per entendre que es capaç de fer, possibles usos e inclus realitzar un model (molt senzill) de classificació automàtica de text.
Més enllà d’una implementació concreta, que veurem en un pròxim article, la idea es ensenyar a grans trets, quina es la “magia” del Machine Learning i comprendre les seves possibilitats i limitacions.
Que és el Machine Learning?
Com es pot veure en el diagrama següent, el Machine Learning (aprenentatge automàtic) es una disciplina dins de la branca de la Intel·ligència Artificial

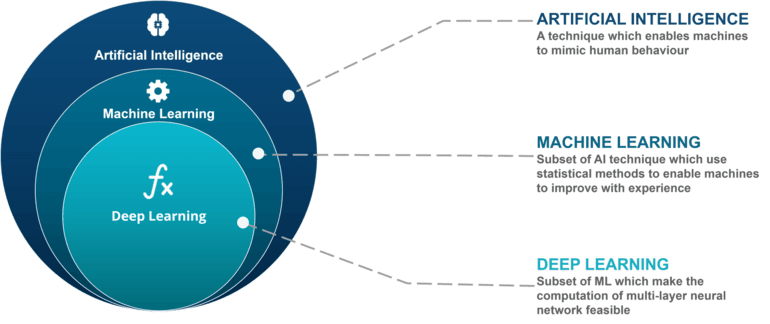
Si ho hagués de resumir diria que consisteix en l’aplicació de algorítmics matemàtics (especialment estadístics) per tal de intentar predir quelcom basant-se en el seu històric. Segur que amb un exemple ho veieu més clar.
Exemples d’us del Machine Learning (ML)
Suposem que volem intentar predir el retard (més probable) que tindrà un vol de Barcelona a Girona. Pensareu que no cal fer un model per trobar una resposta força aproximada a la realitat, que només cal fer una mitja dels retards d’aquest vol dels últims mesos. Doncs si no ens cal ser gaire precisos podria ser suficient, però si volem afinar haurem d’anar més enllà i observar més variables. Sense donar-li gaires voltes, podria ser interessant tenir en compte també:
- L’hora d’enlairament: Potser el pilots van més cansats de nit que de dia.
- El dia de la setmana: Segurament el divendres hi ha més passatgers i per tant es poden generar més retards.
- El dia del mes: Podríem observar si a principi de mes augmenta o disminueix el nombre de passatgers
- El mes: Depenent de l’època de l’any hi haurà més vols i per tant la rapidesa amb la que ens donen permís per enlairar-nos o per aterrar influirà en la durada del viatge.
- El nom dels pilots: És possible que un pilot sigui més propens a arribar tard, parlar amb els passatgers, sigui més hàbil o menys…
- Direcció del vent.
- El model de l’avió: que sigui més ràpid o menys.
- El temps que fa que no se li ha fet una revisió a l’avió
Com veieu podríem tenir moltes variables en compte i generalment quantes més variables observem més fiable serà la predicció (hi han mètodes matemàtics per esbrinar quines variables tenen més relació amb el que estem buscant i en quines la relació és tant dèbil que no val la pena tenir-les en compte). Amb tantes dades ja no es fàcil calcular el retard del vol i és aquí es on una I.A ens pot ajudar.
En aquest cas hauríem de tenir estructurades totes les dades dels últims anys i passar-les pels algoritmes que haguem decidit per tal d’entrenar-lo i obtenir un model que quan li preguntem, per exemple, si el retard d’un vol serà major a 10 minuts ens contesti que les probabilitats son d’un X%.
Hem de tenir en compte que hem de fer “les preguntes” que puguin ser resoltes pel tipus d’algoritme que hem escollit i per les dades que li hem facilitat. Ni podem preguntar per una variable que no coneix (que no està entre les dades que li hem passat) ni podem esperar una resposta numèrica exacte si l’algoritme amb el que estem treballant només és capaç de donar-nos un percentatge de possibilitats.
Tots i que funciona aplicant algoritmes matemàtics i que els ordinadors només saben treballar amb nombres, amb l’ús de diferents tècniques pràcticament tot es pot transformar a nombres. Per exemple, assignant números a paraules, podem aplicar les tècniques i algoritmes de ML a textos de manera que siguem capaços de classificar texts (tweets, articles de premsa, “papers”…) o entenent les imatges com a matrius de píxels en les quals s’indica numèricament el color de cada un d’ells.
Diferencia entre Machine Learning i Deep Learning
L’aprenentatge realitzat per un model de Machine Learning es pot classificar en dos grans grups: supervisat i no supervisat.
- Supervisat: Quan requereix que les dades necessàries per entrenar el model han de ser etiquetades o completades prèviament per una persona. Durant aquest procés és necessari que una persona indiqui al model quines variables ha de fer servir. Per exemple, per l’exercici de classificador de text, haurem de tenir una mostra de textos que hagin sigut prèviament classificades per una persona de manera que li estem indicant indirectament al model quantes categories de texts tenim i el tipus d’aquests hi ha en cada grup.
- No supervisat: En aquest cas entrenaríem el model amb dades “raw” i que per tant no caldria intervenció humana per classificar-les o afegir valor. Aquest tipus d’aprenentatge sobretot es fa servir per descobrir grups, identificar objectes i relacions entre les variables. Si volguéssim classificar texts, un bon algoritme de “deep learning” seria capaç d’agrupar els texts sense que una persona les hagués etiquetat milers de text prèviament. Òbviament no sabria com es diu cada grup (no li estem passant ni el nom dels grups ni indicant el tipus de text que hi ha en cada grup), però seria capaç d’agrupar-les segons el text de cada una d’elles.
En la ultima dècada la I.A ha evolucionat molt gracies a l’ús del “Deep Learning”. Segueix funcionant en base a algoritmes matemàtics pero en combinacions molt més complexes i distribuïdes en capes. És l’aproximació que fins ara, imita més fidelment el comportament del cervell humà i s’acostumar a representar com una xarxa de neurones (xarxa neuronal).

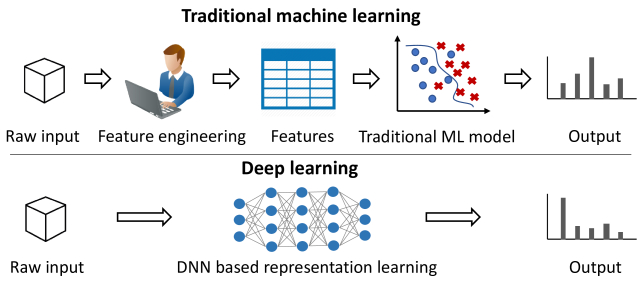
La primera capa s’hi representen les variables d’entrada i en les posteriors es van aplicant algoritmes a cada una d’aquestes variables d’entrada per finalment combinar totes aquestes dades de manera que dongui un sol resultat. L’exemple més clàssic es el reconeixement d’objectes.

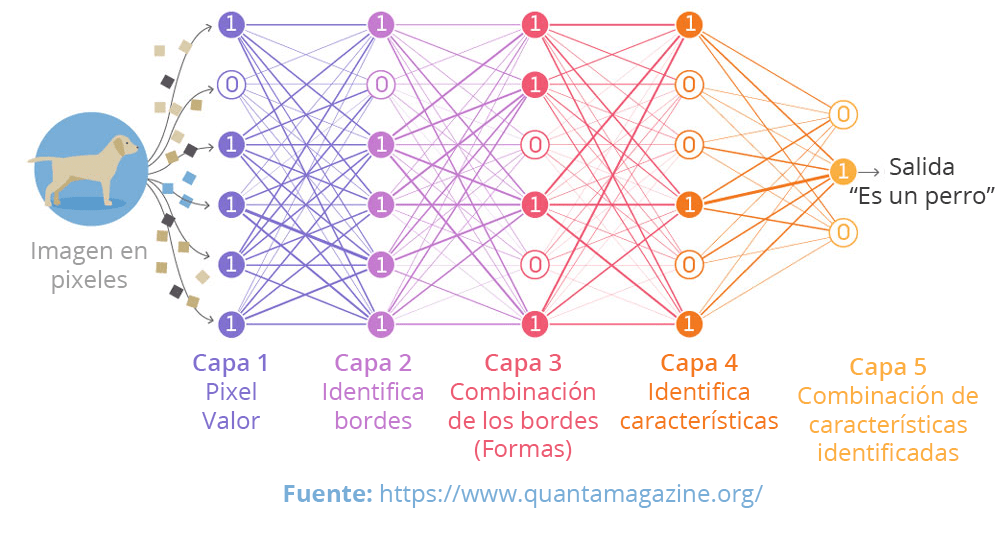
Us deixo l’enllaç a una masterclass molt interessant que van organitzar des del CIDAI on David Hurtado Torán (Customer Success Innovation Lead at Microsoft) explica d’una forma molt didàctica les diferencies entre Machine Learning / Deep Learning, i “l’estat de l’art” actual
Etapes d’un projecte de ML
Com us comentava la inici de l’article, per fer-nos una idea més concreta del que estem parlant, comentarem un model de classificació de text molt senzill que podríem aplicar per la categorització d’incidències.
Com tot projecte, es recomana seguir una serie d’etapes per tal minimitzar els possibles errors maximitzant així les possibilitats d’èxit:
- Definició de l’objectiu.
- Recopilació i preparació de les dades.
- Escollir el model.
- Entrenament del model.
- Avaluació del model.
1. Definició de l’objectiu.
Imaginem que treballem amb un software central on es reben totes les incidències de l’empresa, des de la sol·licitud que demana la creació d’un nou usuari al sistema, fins una reclamació sobre un error en una nòmina. Per tal de facilitar el cribratge de les incidències i que els especialistes només els arribin les incidències que pertanyen al seu àmbit de coneixement, totes les incidències s’han de classificar prèviament en temàtiques/cues.
L’objectiu es crear un model de ML (d’aprenentatge supervisat) que sigui capaç d’esbrinar a quina temàtica/cua pertany una nova incidència. Com és aprenentatge supervisat haurem de disposar d’una quantitat prou gran (de l’ordre de milers) d’exemples que facilitar al model per tal de que aprengui quin tipus d’incidència va a cada cua.
2. Recopilació i preparació de les dades
Abans de facilitar les dades d’exemple al model ens haurem d’assegurar que estan en un format que sigui fàcil de llegir per l’ordinador.
Qualitat de les dades
Totes els valors per una mateixa variable han de tenir el mateix format i la mateixa estructura (normalitzar):
- En cas de tenir camps numèrics, tots els valors d’aquell camp han d’estar en el mateix format, unitat i escala.
- En el cas dels texts haurem d’evitar el text enriquit o que es barregi el text que volem analitzar amb tags HTML, XML etc.
Per exemple, en l’exemple anterior que tractava d’endevinar el retard dels vols, si tinguéssim un camp que informa del retard dels vols, que s’ha informat per diferents persones manualment, podríem tenir valors tant dispars com:
- 12 min
- 12min
- 12
- 720 segons
- 720sec
- 00:12:00h
El model només entendrà el “12” i no sabrà que fer amb la resta de valors d’aquella variable.
Per no complicar l’exemple i poder-nos centrar en el que realment ens interessa, imaginem que ja hem fet gran part de la feina de normalització dels texts i que ens hem descarregat totes les incidències en un CSV on apareguin, al menys, els següents camps:
- La descripció de la incidència.
- A la categoria/cua a la que pertany.
3. Elecció del model
Actualment hi ha 3 grans tipus de models:
- Classificació binaria: destinats a dir si quelcom es veritat o fals.
- Classificació multi-classe: predicció d’un valor de entre més de dos possibles valors. Per exemple el plat preferit d’un client.
- Regressió: prediu un nombre concret, per exemple el numero de gols que marcarà el teu equip de futbol en un partit concret.
Dintre de cada tipus model hi ha diferents algoritmes matemàtics possibles. Per exemple hi ha diferents algoritmes de trobar el plat preferit d’un client i dependrà de l’aproximació que vulguis fer i de les dades que tinguis el que un algoritme et generi millor o pitjors resultats.
4. Entrenar el model
Ara si, ja ho tenim tot llest per començar a programar l’entrament del model.
Els llenguatges més coneguts per crear projecte de Machine learning es R, Python i Java. Us recomano començar a aprendre ML en Python ja que es el més pràctic per fer les primeres passes ja que existeixen multitud de llibreries que ajuden moltíssim i una quantitat molt gran d’exemples i documentació.
A més a més, existeix el projecte JupyterNotebook que permet programar Python des de una interfície web, poden executar el codi per línies de manera que pots executar nomes un part del codi tantes vegades com vulguis però mantenint els estats de les variables i objectes amb els valors obtinguts de les línies anteriors sense tenir que executar-les un altre cop. És molt pràctic quan es treballa amb operacions que poden tardar molta estona en executar-se com es el cas dels projectes de ML.
Fins aquí la part teòrica de l’exemple. Si voleu veure una implementació en Python molt senzilla d’un model classificador d’incidències, he escrit un article de com fer-ho utilitzant NL (Natural Language).
Conclusió
Hem vist que la tecnología està en un punt que ens permet predir molt millor que amb les tècniques clàssiques. Ja hi ha molta documentació i eines que en “democratitzen” moltíssim l’accés i que per tant val la pena incloure-la sense “por” en els projectes que en puguin sortir beneficiats.