

Com us comentava en el post anterior, anem a “aterrar” un exemple pràctic de com implementar un senzill classificador de text, més concretament un classificador d’incidències
Escollir llenguatge
Tornant al que us comentava en l’anterior article, els llenguatges més coneguts per crear projecte de Machine learning són R, Python i Java. No conec gaire R però em sembla menys versàtil que els altres dos. Per l’altre banda tot i que Java es molt conegut i robust, he trobat més continguts sobre ML en Python i a més a més crec que és més pràctic per fer les primeres passes (menys estructura que modificar en cada iteració de prova/error) per tant escollirem aquest llenguatge per apendre.
A més a més, existeix el projecte JupyterNotebook que permet programar Python des de una interfície web, poden executar el codi per línies de manera que pots executar nomes un part del codi tantes vegades com vulguis però mantenint els estats de les variables i objectes amb els valors obtinguts de les línies anteriors sense tenir que executar-les un altre cop. Es molt pràctic quan es treballa amb operacions que poden tardar molta estona en executar-se com es el cas dels projectes de ML.
Les dades
Pel nostre exemple, comptarem amb un fitxer CSV amb més de 80.000 incidències correctament categoritzades.
També podríem afegir el camp que informa de la persona que ha escrit la incidència ja que ens pot ajudar a saber de quin tipus d’incidència es tracta ja que habitualment un treballador posa tipus d’incidència similars. Per exemple un treballador de magatzem, pel tipus de feina que fa, serà més propens a posar una incidència al departament de manteniment que al departament de comptabilitat.
Així doncs, el fitxer tindrà la següent estructura:
- caller_id: Nom de la persona que ha escrit la incidència.
- short_description: Assumpte de la incidència o descripció curta.
- description: La descripció completa.
- assignment_group: Categoria o cua a la que està assignada la incidència.
Com parlàvem en l’article anterior es molt important la qualitat de les dades. Per la font d’on provenen les dades, en aquests cas no ha calgut fer neteja però si el software guardes el text en algun tipus de format enriquit (per exemple HTML) abans d’avançar i entrenar al model, hauríem pulir les dades.
Després de provar diferents algoritmes (no entrarem en les proves realitzades en aquest article), en el nostre exemple farem servir l’algoritme de classificació multi-classe anomenat “Linear Support Vector Classification“
Entrant en matèria
El primer de tot és llegir les dades d’entrenament, en aquest cas incidències
import pandas as pd
import csv
print("Leyendo datos de entrenamiento");
df = pd.read_csv("DataSets/TOTES_LES_INCIDENCIES_v4.csv", encoding = "ISO-8859-1")Com veieu hem d’instal·lar e importar les llibreries Panda, molt conegudes pels programadors de Python. Aquestes ens permetran crear un DataFrame (objecte per manipular dades obtingudes d’una font de dades estructurades) amb les dades llegides del fitxer CSV on tenim totes les incidències.
Per evitar inconsistències de dades tenint en compte dades incompletes, s’esborren del DataFrame les línies que no tenen tots els camps informats.
df = df.dropna(subset = ["caller_id","short_description","description","assignment_group"])
Per tal de que el model tingui en compte el nom de la persona que ha creat la incidència, crearem un camp nou en el DataFrame on unirem el nom d’aquesta persona amb la del text de la descripció. Aquest es el camp amb el que treballarem a partir d’ara.
df['concatenat'] = df['caller_id'] +'.\r\n'+ df['short_description']
Com l’ordinador només “entén” números, n’ hem d’assignar un a cada categoria/cua. El model treballa amb aquests identificadors i nomes quan vulguem mostrar els resultats podrem tornar a relacionar aquests identificadors amb la seva descripció corresponent.
Per fer-ho correctament ho hem de fer amb la funció factorize del dataFrame que ens crearà una nova columna en el DataFrame amb el numero que li correspon a la categoria a la que esta assignada la incidència
df['category_id'] = df['assignment_group'].factorize()[0]
Abans de començar amb algoritmes reduirem el nombre de paraules amb les que haurà de treballar.
Primer una funció lambda per convertir totes les majúscules a minúscules de manera que la mateixa paraula amb o sense majúscules no pugui ser interpretada com dos paraules diferents.
Després utilitzarem la llibreria Spacy per obtenir-ne la llista de STOP_WORDS corresponent a l’idioma dels text, en el nostre cas, el espanyol. Aquesta llista conté articles, salutacions freqüents, signes de puntuació… paraules que extraurem del text per tal d’optimitzar l’entrenament del model.
from spacy.lang.es.stop_words import STOP_WORDS as es_stop
from io import StringIO
import string
df['concatenat'] = df['concatenat'].apply(lambda fila: fila.lower())
final_stopwords_list = list(es_stop)
final_stopwords_list.append('\r\n')
final_stopwords_list.append(string.punctuation)I ara arribem a una de les parts més importants de l’entrenament d’un model ML basat en Natural Language (NL), la transformació de les paraules en vectors de números. En aquest cas el millor algoritme que hem trobat és el de fer-ho en base a la freqüència en la que apareixen aquestes paraules en el text. Per exemple per el text 1 tindrem un vector on cada paraula ocupa una posició en ell i el valor d’aquesta posició es un valor entre 0 i 1 que indica la freqüència en la que apareix en aquest text.
tfidf = TfidfVectorizer(sublinear_tf=True, min_df=5, norm='l2', encoding='latin-1', ngram_range=(1, 2), stop_words=final_stopwords_list,max_features=5000) features = tfidf.fit_transform(df.concatenat).toarray() labels = df.category_id
Dels paràmetres que li passem al constructor cal destacar:
- ngram_range = el rang de conjunts de paraules que creiem que tenen significat per elles soles. En aquesta cas estem indicant que analitzi conjunts entre 1 i 2 paraules.
- stop_words = llistat de paraules que no volem que analitzi per tal d’optimitzar el procés i no quedi contaminat per paraules que no ajuden a classificar el text.
- max_features = mida màxima del vector de paraules analitzades per cada text. En cas de disposar de poca memòria RAM es pot mirar de “jugar” amb aquest paràmetre.
Per ultim, preparem els noms de les diferents categories on voldrem encabir els nostres texts en vector associatius
Ara ja tenim les dades preparades per entrenar el model pròpiament. Per fer-ho utilitzarem la llibreria més famoses de ML en Python, la Sklearn. Per aquest exemple, ens interessen dos coses d’aquesta llibreria:
- La funció train_test_split: ens permet dividir fàcilment totes les incidències prèviament classificades, en dos grups, un grups que ens servirà per entrenar el model i un altre grup que ens servirà per provar el model després de ser entrenat, de manera que ens indiqui que tant bo és el model classificant les incidències. Com veurem en l’exemple li hem estipulat que provi el model amb el 20% de les dades de manera que l’altre 80% el farem servir per entrenar el model. Òbviament li haurem de passar tant les incidències com els grups en el que l’ha de classificar. Com veiem aquesta funció ens torna 6 vectors, tres per cada conjunt de dades.
- L’algoritme que farem servir per classificar les incidències: En aquest cas el que millors resultats he obtingut es el LinearSVC.
Tots els algoritmes de la llibreria tenen una funció “fit” a la que hem de passar-li els dos vector de dades d’entrenament. Un cop entrenat el model cridarem a la funció “predict” que provarà el model amb les incidències del grup de test. Això ens permetrà valorar l’eficàcia que hem aconseguit amb aquest algoritme de classificació i els paràmetres configurats.
from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVC model = LinearSVC() X_train, X_test, y_train, y_test, indices_train, indices_test = train_test_split(features, labels, df.index, test_size=0.2, random_state=0) model.fit(X_train, y_train) y_pred = model.predict(X_test)
Com es pot veure aquestes llibreries faciliten moltíssim la tasca ja que incorporen moltíssims algoritmes i estandarditza el codi per utilitzar-los.
Avaluació del model
Per fi podem veure el resultat de tota la feina prèvia. Primer obtindrem una llista dels noms de totes les categories/temàtiques en les que es podien classificar els texts i posteriorment “printarem” la taula de mètriques corresponent als resultats obtinguts
from sklearn import metrics
unic_label_train = df.groupby(['assignment_group'])['assignment_group'].size()
unic_label_train = unic_label_train[unic_label_train].index.get_level_values(0).tolist()
print(metrics.classification_report(y_test, y_pred,
target_names=unic_label_train))Obtindrem una taula com aquesta (he amagat els noms de les categories reals ja que estic fent servir un conjunt de dades privades)
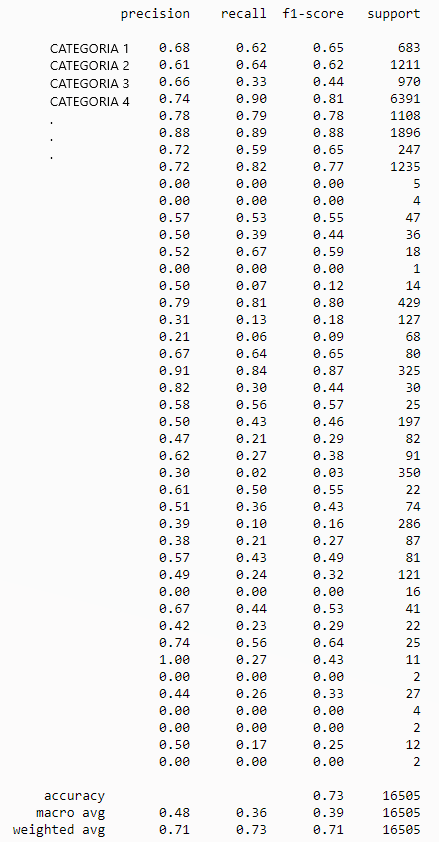
A simple vista veurem una dos seccions, la part superior on per cada categoria tindrem les seves mètriques especifiques i la part inferior on tenim el resultat general. El significat de les diferents columnes és aquest.
- precision: És la relació entre les prediccions correctes i el número total de prediccions correctes previstes (precisió a l’hora de predir casos positius)
- recall: Es la relació entre les prediccions positives correctes i el nombre total de prediccions positives.
- f1-score: la mitja de les dues anteriors, vindria a ser la puntuació general de lo bo que és el model en la seva tasca.
Per tant podem comprovar que hem aconseguit una eficàcia (accuracy) general del 73% d’una forma molt senzilla.
Si ens detenim una mica més veurem que per algunes categories, tenim una eficiència molt baixa. Això pot ser degut a diferents problemes:
- No hi ha prou incidències d’aquella categoria i per tant el model no s’ha entrenat prou be per identificar-les.
- El textos de les incidències entre algunes categories són molt semblants i no es capaç de distingir correctament a quin grup pertanyent.
- Textos poc específics (contenen poques paraules “claus”)
- Falta d’optimització del paràmetres configurats a l’algoritme.
Notar que en l’entrenament del model hem deixat els paràmetres per defecte de l’algoritme. Normalment els valors per defecte son els que ofereixen uns valors mitjos més bons, però si volguéssim aprofundir i treure millors resultats hauríem d’estudiar que fa cada un dels paràmetres de l’algoritme (en aquest cas el LinearSVC) i tractar de trobar la millor combinació d’aquests. Hi han mètodes automàtics que mitjançant la “força bruta” et diuen la combinació més optima de paràmetres però només els recomano per projectes que vagin a producció ja que trobar un millor combinació requereix una gran quantitat de recursos computacionals i temps. Per fer una aproximació, els paràmetres per defecte ofereixen bon resultats.
Podeu trobar el codi sencer en el meu repositori de GitHub.
Conclusió
Com hem vist no calen grans projectes per poder aplicar tècniques de Machine Learning, poden ser projectes molt modestos, però el que si necessitarem són forces exemples.
Aquest només era un exemple molt senzill i que pràcticament es fa “sol”, nomes cal preparar una mica les dades, “concatenar” un parell de funcions de les llibreries i veure’n els resultats. Gracies a les llibreries que hem instal·lat, canviant molt poques instruccions podem provar amb diferents algoritmes i comprovar quin ens ofereix millors resultats per al nostre cas.
Pot sorprendre que no ens han calguts grans coneixements de estadística per muntar-lo. Això es degut a que les llibreries que hem utilitzat ja incorporen els algoritmes més útils i que de segur cobriran bona part dels possibles cas d’us. De totes maneres si volguéssim “jugar” amb les dades, comparar algoritmes, afinar les prediccions, etc si que ens hagués calgut uns bons coneixement d’estadística.
Per ultim, si voleu veure més exemples pràctics, existeix Kaggle que es una web on empreses i particulars poden demanar ajuda en projectes reals de “machine learning” i la comunitat els pot ajudar de forma desinteressada o interessada (freqüentment les empreses recompensen els individuu que els ha proporcionat una solució al problema plantejat). Normalment el codi es comparteix de manera publica per a que sigui útil a la resta de la comunitat i per tant es una font molt interessant de coneixement.