

Introducció
Segueixo fent proves amb el compte GPT plus i aquest cop volia entendre amb més detall el procés que segueix un model de I.A per respondre preguntes relacionades amb una documentació que li facilitem i entendre’n la complexitat/reptes que suposa. Des de fa uns mesos s’ha popularitzat un mètode molt efectiu anomenat RAG (Retrieval-Augmented Generation) i ha arribat el moment de posar-li les mans a sobre.
Objectiu
Primerament la meva intenció és que el model hem respongui dades dels meus articles de la web. No en tinc gaires però tenen una llargària semblant a la que podria ser un document mig.
Més endavant ho intentarem fer amb documents més llargs i menys estructurats per acostar-nos més a un cas “real” on una petita empresa vol utilitzar un model de I.A per a que els seus treballadors obtinguin informació dels documents corporatius.
Requisits
Bé, veureu que pel mètode fàcil (utilitzar les llibreries amb models de chatGPT) compte GPT plus i com és evident els documents dels quals voleu que respongui les preguntes. Quan veiem com fer el mateix amb models open-source nomes necessitareu tindre un compte en Hugging Face.
Per la prova amb documents estructurats, necessitaré les URL’s dels meus articles anteriors, però realment ho podeu fer amb altres documents JSON que tingueu. Per la prova amb documents no estructurats jo m’he descarregat la presentació de resultats de Telefònica dels últims 4 anys, però us servira qualsevol fitxer PDF.
També necessitareu un entorn de programació de Python (el llenguatge per excel·lència per treballar amb I.A). Jo he fet servir el Jupyter Notebook que és molt pràctic per fer aquest tipus de prova però realment nomes necessiteu instal·lar el Python i tenir un aplicació que permeti crear/modificar un fitxer de text pla.
Entenen la “memoria” d’un model LLM (Large Language Model)
Abans d’entrar en matèria cal saber com funciona la “memòria” dels models LLM. Tot i que no ho comento en l’article anterior (on parlava de com crear un chat GPT personalitzat) als agents GPT també els pots adjuntar documents per a que els tingui en compte, però tota la informació/personalització que feu servir per configurar el vostre agent propi agent, realment serveix com a capçalera del vostres futurs “prompts” (preguntes) cada cop que en feu un.
“Ets un assistent virtual que m’ajudaràs en les tasque diàries, entre elles la creació d’events i recordatoris en el meu Google Calendar. Crea’m un esdeveniment al calendari pel pròxim divendres a les 9 i mitja amb el títol ‘Crear un nou article al web'”

Amb un exemple s’entendrà molt fàcilment. Imaginem que en la configuració de l’agent li heu dit “Ets un assistent virtual que m’ajudaràs en les tasque diàries, entre elles la creació d’esdeveniments i recordatoris en el meu Google Calendar”. Un cop ja el tingueu configurat i li vulgueu demanar “Crea’m un esdeveniment al calendari pel pròxim divendres a les 9 i mitja amb el títol ‘Crear un nou article al web'”, realment el que li esteu dient és:
A aquest “prefix”, se l’anomenta “context”. I això funciona perfectament, però els models tenen limitacions en quan a la quantitat de tokens/paraules que són capaces de tenir en el context. Els més nous (GPT4o) podrien tenir un llibre d’unes 300 pagines aproximadament com a context, que es clarament insuficient per fer encabir, ni tan sols tota la nostra informació personal (mails, documents legals, factures, etc…)
Per evitar aquesta limitació tenim 2 alternatives:
- Vectoritzar els documents en “embeddings” (vector de dades).
- Que els documents formin part de les dades d’un procés “fine-tunning” (re-entrenar el model).
A grans trets (més endavant ho explicaré amb molt més detall) el que farem en la primera alternativa serà preguntar a un algoritme d’indexació quin/s document/s són els més rellevants per a la pregunta que estem fent, recuperar el tros del document/s que és el realment rellevant i passar-li com a context al nostre model perquè n’extregui la informació necessària per poder respondre’ns.
El segon mètode funciona totalment diferent. Consisteix en fer un petit entrament extra al model de I.A per a que “memoritzi” els documents. Això permet que no ens haguem de preocupar de passar al model una part del/s documents com a context, sinó que el model “memoritzarà” els documents internament. Te un cost computacional major i té la desavantatge de que l’estaràs entrenant amb el contingut que tinguin els documents en aquell moment, per tant si fas preguntes sobre informació continguda en documents “vius”, t’estarà contestant amb informació desfasada.
Heu de tenir en compte que normalment les empreses que ofereixen serveis al núvol de inferència amb models de I.A solen facturar pel nombre de tokens d’entrada (context + prompt) i els de sortida (la resposta que et dona el model) per tant la segona opció es més eficient en aquest sentit.
La millor estratègia a l’hora d’implementar I.A tant per l’ús domèstic com per l’ús empresarial seria fer un “fine-tunning” de tot allò que no pot canviar (històric) però anar vectoritzant la resta d’informació.
Preparar les dades
Segurament el més complicat de tot el procés és polir i transformar les dades. Tot i que no són processos obligatoris si que són molt recomanables per obtenir millors resultats de la cerca.
Per fer les proves amb documents estructurats, com són articles del meu web (i escric fantàsticament bé 😉 ) i no gaire llargs no serà necessari, però habitualment s’hauria de vigilar aquest punts:
- Eliminació de caràcters especials i puntuació: Treure caràcters que no siguin necessaris per a l’anàlisi, com puntuació excessiva, emojis, o caràcters no alfabètics.
- Correcció ortogràfica: Corregir errors ortogràfics per assegurar la consistència del text.
- Normalització de text: Convertir tot el text a minúscules per evitar diferències causades per majúscules/minúscules.
- Documents duplicats: Eliminar documents que són exactament iguals.
- Fragments duplicats: Eliminar paràgrafs o frases que es repeteixen dins d’un mateix document o entre diferents documents.
- Temàtica: Assegurar que els documents tractin del tema d’interès.
- Qualitat: Filtrar documents amb poca informació, massa curts o de baixa qualitat.
Amb documents no estructurats és molt recomanable passar-los per un procés que els dongui una estructura comú i converteixi el contingut en text pla, tot i que després veurem que la aquest mètode (RAG) m’ha semblat que no és tant sensible al format com els anteriors (TF-IDF). Si decidim homogenionitzar la documentació haurem de revisar aquests assumptes:
- Identificació de títols, autors, dates: Extreure i estructurar metadades importants dels documents.
- Classificació temàtica: Assignar etiquetes temàtiques o categories als documents.
- Format de text: Convertir documents a un format de text pla si estan en formats complexos com PDF, Word, HTML, etc.
- Codificació de caràcters: Assegurar que el text estigui en una codificació de caràcters uniforme, com per exemple UTF-8.
Per la primera aproximació faré servir els articles de la web que al final son documents estructurats, però com tenen elements que poden confondre el model, els transformaré en un fitxer JSON amb una estructura molt simple (títol de l’article, URL de la font i el contingut/text de l’article)
{
"title": ,
"url": ,
"content": {
"Capitol 1": [
],
"Capitol 2": [
],
.
.
.
}
}El transformar els articles a fitxer JSON he fet servir el següent codi:
import requests
from bs4 import BeautifulSoup
import json
import re
def fetch_article(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extrect el titol de l'article
title = soup.find('h1', class_='entry-title').text.strip()
# Extrect el contingut de l'article
content_div = soup.find('div', class_='entry-content')
elements = content_div.find_all(['h2', 'p'])
# Organitzo el contingut per capitols
article_content = {}
current_chapter = "Introduction" #Capitol per defecte per cualsevol text anterior al primer H2
article_content[current_chapter] = []
for element in elements:
if element.name == 'h2':
current_chapter = element.text.strip()
article_content[current_chapter] = []
elif element.name == 'p':
article_content[current_chapter].append(element.text.strip())
# Preparo l'estructura del JSON
article_json = {
"title": title,
"url": url,
"content": article_content
}
return article_json
def extract_last_non_empty_word(url):
# Utilitzar una expressió regular per trobar totes les paraules entre les barres invertides
matches = re.findall(r'/([^/]*)', url)
# Filtrar les coincidències per eliminar les buides
non_empty_matches = [match for match in matches if match]
# Retornar l'última paraula no buida o None si no hi ha coincidències
return non_empty_matches[-1] if non_empty_matches else None
def save_article_to_json(article_json, file_path):
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(article_json, f, ensure_ascii=False, indent=4)
print(f"Article saved to {file_path}")
# URL's dels articles
urls = [
"https://arnaudunjo.com/ca/2024/07/07/creacio-dun-chatgpt-personalitzat-agent-gpt/",
"https://arnaudunjo.com/ca/2023/01/31/generant-codi-amb-gpt-3/",
"https://arnaudunjo.com/ca/2021/10/04/alarma-domestica-amb-raspberry-pi/",
"https://arnaudunjo.com/ca/2021/04/25/introduccio-al-machine-learning-aprenentatge-automatic/",
"https://arnaudunjo.com/ca/2021/04/25/machine-learning-model-classificador-de-textos-en-python/",
"https://arnaudunjo.com/ca/2021/02/11/millorant-la-seguretat-i-la-privacitat-en-les-comunicacions-amb-raspberry-pi/",
"https://arnaudunjo.com/ca/2021/01/13/opinio-moonlander-mk1/",
"https://arnaudunjo.com/ca/2020/12/17/desenvolupament-duna-aplicacio-blockchain-desde-0-amb-python/"
]
for url in urls:
last_word = extract_last_non_empty_word(url)
# Paso el continguta a JSON
article_json = fetch_article(url)
# Guardo el fitxer JSON
file_path = last_word + ".json"
save_article_to_json(article_json, file_path)
De tot l’script el complicat es la funció que “parseja” el contingut i el transforma en l’estructura que us comentava (fetch_article). Per resumir-ho una mica consisteix en invocar un parser de HTML i separar el contingut pels tres tipus de tags HTML que m’interessen:
- El textos en els tags H1 els considero el títol.
- Els textos en els tags H2 els considero els capítols.
- Els textos en els tags P els considero els contingut de cada un dels capítols.
Aplico aquesta funció per cada un dels articles i guardo el contingut en fitxers diferents amb extensió .json
Els fitxers generats es guarden amb l’estructura que comentava anteriorment, per exemple:
{
"title": "Machine Learning: Model classificador de textos en Python",
"url": "https://arnaudunjo.com/ca/2021/04/25/machine-learning-model-classificador-de-textos-en-python/",
"content": {
"Introduction": [
"Com us comentava en el post anterior, anem a “aterrar” un exemple pràctic de com implementar un senzill classificador de text, més concretament un classificador d’incidències"
],
"Escollir llenguatge": [
"Tornant al que us comentava en l’anterior article, els llenguatges més coneguts per crear projecte de Machine learning són R, Python i Java. No conec gaire R però em sembla menys versàtil que els altres dos. Per l’altre banda tot i que Java es molt conegut i robust, he trobat més continguts sobre ML en Python i a més a més crec que és més pràctic per fer les primeres passes (menys estructura que modificar en cada iteració de prova/error) per tant escollirem aquest llenguatge per apendre.",
"A més a més, existeix el projecte JupyterNotebook que permet programar Python des de una interfície web, poden executar el codi per línies de manera que pots executar nomes un part del codi tantes vegades com vulguis però mantenint els estats de les variables i objectes amb els valors obtinguts de les línies anteriors sense tenir que executar-les un altre cop. Es molt pràctic quan es treballa amb operacions que poden tardar molta estona en executar-se com es el cas dels projectes de ML."
],
"Les dades": [
"Pel nostre exemple, comptarem amb un fitxer CSV amb més de 80.000 incidències correctament categoritzades.",
"També podríem afegir el camp que informa de la persona que ha escrit la incidència ja que ens pot ajudar a saber de quin tipus d’incidència es tracta ja que habitualment un treballador posa tipus d’incidència similars. Per exemple un treballador de magatzem, pel tipus de feina que fa, serà més propens a posar una incidència al departament de manteniment que al departament de comptabilitat.",
"Així doncs, el fitxer tindrà la següent estructura:",
"Com parlàvem en l’article anterior es molt important la qualitat de les dades. Per la font d’on provenen les dades, en aquests cas no ha calgut fer neteja però si el software guardes el text en algun tipus de format enriquit (per exemple HTML) abans d’avançar i entrenar al model, hauríem pulir les dades.",
"Després de provar diferents algoritmes (no entrarem en les proves realitzades en aquest article), en el nostre exemple farem servir l’algoritme de classificació multi-classe anomenat “Linear Support Vector Classification“"
],
"Entrant en matèria": [
"El primer de tot és llegir les dades d’entrenament, en aquest cas incidències",
"Com veieu hem d’instal·lar e importar les llibreries Panda, molt conegudes pels programadors de Python. Aquestes ens permetran crear un DataFrame (objecte per manipular dades obtingudes d’una font de dades estructurades) amb les dades llegides del fitxer CSV on tenim totes les incidències.",
"Per evitar inconsistències de dades tenint en compte dades incompletes, s’esborren del DataFrame les línies que no tenen tots els camps informats.",
"Per tal de que el model tingui en compte el nom de la persona que ha creat la incidència, crearem un camp nou en el DataFrame on unirem el nom d’aquesta persona amb la del text de la descripció. Aquest es el camp amb el que treballarem a partir d’ara.",
"Com l’ordinador només “entén” números, n’ hem d’assignar un a cada categoria/cua. El model treballa amb aquests identificadors i nomes quan vulguem mostrar els resultats podrem tornar a relacionar aquests identificadors amb la seva descripció corresponent.",
"Per fer-ho correctament ho hem de fer amb la funció factorize del dataFrame que ens crearà una nova columna en el DataFrame amb el numero que li correspon a la categoria a la que esta assignada la incidència",
"Abans de començar amb algoritmes reduirem el nombre de paraules amb les que haurà de treballar.",
"Primer una funció lambda per convertir totes les majúscules a minúscules de manera que la mateixa paraula amb o sense majúscules no pugui ser interpretada com dos paraules diferents.",
"Després utilitzarem la llibreria Spacy per obtenir-ne la llista de STOP_WORDS corresponent a l’idioma dels text, en el nostre cas, el espanyol. Aquesta llista conté articles, salutacions freqüents, signes de puntuació… paraules que extraurem del text per tal d’optimitzar l’entrenament del model.",
"I ara arribem a una de les parts més importants de l’entrenament d’un model ML basat en Natural Language (NL), la transformació de les paraules en vectors de números. En aquest cas el millor algoritme que hem trobat és el de fer-ho en base a la freqüència en la que apareixen aquestes paraules en el text. Per exemple per el text 1 tindrem un vector on cada paraula ocupa una posició en ell i el valor d’aquesta posició es un valor entre 0 i 1 que indica la freqüència en la que apareix en aquest text.",
"Dels paràmetres que li passem al constructor cal destacar:",
"Per ultim, preparem els noms de les diferents categories on voldrem encabir els nostres texts en vector associatius",
"Ara ja tenim les dades preparades per entrenar el model pròpiament. Per fer-ho utilitzarem la llibreria més famoses de ML en Python, la Sklearn. Per aquest exemple, ens interessen dos coses d’aquesta llibreria:",
"Tots els algoritmes de la llibreria tenen una funció “fit” a la que hem de passar-li els dos vector de dades d’entrenament. Un cop entrenat el model cridarem a la funció “predict” que provarà el model amb les incidències del grup de test. Això ens permetrà valorar l’eficàcia que hem aconseguit amb aquest algoritme de classificació i els paràmetres configurats.",
"Com es pot veure aquestes llibreries faciliten moltíssim la tasca ja que incorporen moltíssims algoritmes i estandarditza el codi per utilitzar-los."
],
"Avaluació del model": [
"Per fi podem veure el resultat de tota la feina prèvia. Primer obtindrem una llista dels noms de totes les categories/temàtiques en les que es podien classificar els texts i posteriorment “printarem” la taula de mètriques corresponent als resultats obtinguts",
"Obtindrem una taula com aquesta (he amagat els noms de les categories reals ja que estic fent servir un conjunt de dades privades)",
"A simple vista veurem una dos seccions, la part superior on per cada categoria tindrem les seves mètriques especifiques i la part inferior on tenim el resultat general. El significat de les diferents columnes és aquest.",
"Per tant podem comprovar que hem aconseguit una eficàcia (accuracy) general del 73% d’una forma molt senzilla.",
"Si ens detenim una mica més veurem que per algunes categories, tenim una eficiència molt baixa. Això pot ser degut a diferents problemes:",
"Notar que en l’entrenament del model hem deixat els paràmetres per defecte de l’algoritme. Normalment els valors per defecte son els que ofereixen uns valors mitjos més bons, però si volguéssim aprofundir i treure millors resultats hauríem d’estudiar que fa cada un dels paràmetres de l’algoritme (en aquest cas el LinearSVC) i tractar de trobar la millor combinació d’aquests. Hi han mètodes automàtics que mitjançant la “força bruta” et diuen la combinació més optima de paràmetres però només els recomano per projectes que vagin a producció ja que trobar un millor combinació requereix una gran quantitat de recursos computacionals i temps. Per fer una aproximació, els paràmetres per defecte ofereixen bon resultats.",
"Podeu trobar el codi sencer en el meu repositori de GitHub."
],
"Conclusió": [
"Com hem vist no calen grans projectes per poder aplicar tècniques de Machine Learning, poden ser projectes molt modestos, però el que si necessitarem són forces exemples.",
"Aquest només era un exemple molt senzill i que pràcticament es fa “sol”, nomes cal preparar una mica les dades, “concatenar” un parell de funcions de les llibreries i veure’n els resultats. Gracies a les llibreries que hem instal·lat, canviant molt poques instruccions podem provar amb diferents algoritmes i comprovar quin ens ofereix millors resultats per al nostre cas.",
"Pot sorprendre que no ens han calguts grans coneixements de estadística per muntar-lo. Això es degut a que les llibreries que hem utilitzat ja incorporen els algoritmes més útils i que de segur cobriran bona part dels possibles cas d’us. De totes maneres si volguéssim “jugar” amb les dades, comparar algoritmes, afinar les prediccions, etc si que ens hagués calgut uns bons coneixement d’estadística.",
"Per ultim, si voleu veure més exemples pràctics, existeix Kaggle que es una web on empreses i particulars poden demanar ajuda en projectes reals de “machine learning” i la comunitat els pot ajudar de forma desinteressada o interessada (freqüentment les empreses recompensen els individuu que els ha proporcionat una solució al problema plantejat). Normalment el codi es comparteix de manera publica per a que sigui útil a la resta de la comunitat i per tant es una font molt interessant de coneixement.",
""
]
}
}Val ara ja tenim les dades en fitxer JSON ja podem passar a indexar-los.
Indexació dels documents
Amb la API de GPT
En Python utilitzarem la llibreria llama-index que ens farà tota la feina, des de llegir el continguts dels documents fins a tornar-los la resposta del model.
Fitxers estructurats
Com veureu es un procés extremadament senzill (dues línies de codi) però a la vegada molt fosc ja que nomes tens una visió molt global del que fa.
import os
import openai
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
from llama_index.core.llms import LLM
from llama_index.llms.openai import OpenAI
import textwrap
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
os.environ["OPENAI_API_KEY"] = "ESCRIU AQUI LA TEVA CLAU API GPT"
# Defineix el camí de la carpeta que vols verificar
directory_path = "./storage"
# Utilitza os.path.exists() per comprovar si el camí existeix
if os.path.exists(directory_path):
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir=directory_path)
# load index
index = load_index_from_storage(storage_context)
else:
# construeixo l'index
documents = SimpleDirectoryReader("documents").load_data()
# el carrego en memoria
index = VectorStoreIndex.from_documents(documents)
# l'escric al disc per no tenir que tonar-lo a crear de 0 cada vegada
index.storage_context.persist()
# creo un query engine en base a la documentació vectoritzada
query_engine = index.as_query_engine()
context = "Respon sempre en català."
pregunta = "Quina eficiencia global tenia l'algoritme de Machine Learning que vaig desenvolupar?"
prompt = context + pregunta
resposta = query_engine.query(prompt)
print (resposta)Bàsicament, sinó existeix l’index en el disc dur el construeixo, els carrego en memòria i el guardo en el disc dur per no tenir que refer-lo cada cop. Si ja existeix l’index simplement el carrego en memòria. Després nomes s’ha d’obtenir l’objecte que et permet “preguntar” als documents i passar-li el “prompt”.
Com són pocs documents i relativament curts, crear l’indexar no ha invertit ni 4 segons. Per simplement carregar-lo en memòria ha tardat un 1 segon aproximadament. Si posem 6 documents en pdf’s d’unes 150 pagines tarda uns 50 segons en vectoritzar i carregar en memòria i 16 segons si únicament ha de llegir l’index del disc dur i carregar-lo en memòria
Si us fixeu aquest procés és tant poc transparent que no sabríem ni que està enviant informació dels documents com a context al model, és gairebé màgia. De fet com estem utilitzant els paràmetres per defecte, no sabem ni quin model estem fent servir (GPT 3.5, GPT 4…). Això en concret és molt senzill, només hem d’afegir dues línies, però segueixes sense tenir visibilitat del que està fent.
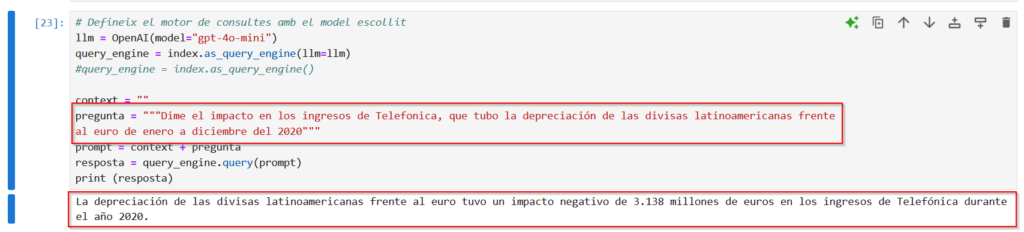
# Defineix el motor de consultes amb el model escollit llm = OpenAI(model="gpt-4o-mini") query_engine = index.as_query_engine(llm=llm) context = "Respon sempre en català." pregunta = "Quina eficiencia global tenia l'algoritme de Machine Learning que vaig desenvolupar?" prompt = context + pregunta resposta = query_engine.query(prompt) print (resposta)

Fitxers no estructurats
Anem a aproximar-nos una mica més a un cas d’ús real, on molt documents no son estructurats (ja sabeu, Word, PDF…). Com us comentava, em vaig baixar els documents de presentació de resultats de Telefònica (des del 2020 al 2024), que al ser una empresa cotitzada en la Bolsa Espanyola, són de domini públic.

Busquem quina pregunta podem fer-li al model i trobem aquest trosset en la presentació de resultats de l’any 2020

I bàsicament ja està, no cal fer res més les llibreries s’encarreguen de fer tota la màgia. Es igual el tipus de fitxer que hagi de llegir
Amb models de codi obert
La veritat és que vaig fer unes proves similars fa cosa d’un any i era força més complicat i el procés no podia amb documents llargs (en el meu ordinador). Amb les noves llibreries que han anat sorgint és bastant més fàcil i potent.
La major dificultat és pel fet de que els grans models necessiten més recursos computacionals del que té el meu ordinador d’escriptori, per tant, he hagut de buscar la manera de fer la prova de concepte sense tenir que muntar gaire infraestructura. L’opció més ràpida ha sigut utilitzar els “spaces” públics de Hugging Face.
Per qui no conegui Huggins Face és un portal amb una enorme comunitat dedicada al Machine Learning i models d’I.A. Allí podeu provar els últims models que han sortit, comparar-los, mesurar el seu rendiment etc.
En aquest cas ens aprofitarem dels acords que tenen amb diferents proveïdors que cedeixen infraestructura (maquines virtuals) al nuvol per provar els models . Per exemple gracies a l’acord entre Hugging Face i Gradio podem disposar d’una maquina modesta (2vCPU i 16GB de RAM) totalment gratuïta per fer proves. Cada una d’aquestes maquines virtuals (realment son contenidors Docker) i la seva configuració es el que forma un “space”. Cada compte d’usuari a Hugging Face pot tenir infinits(?) “spaces” i en cada un d’ells tenir corrent un model de I.A.
Com que som persones pràctiques, buscarem un space que contingui el model que ens agradaria provar (en aquest cas el model LLama 3.1 de 8B)
Un cop dins ens apareixerà una interfície de xat (finestra gran on veure l’històric de la conversa) i un camp d’entrada de text a la part inferior on posar el “prompt”. Podem “jugar” amb aquest xat però el que realment ens interessa és provar-lo en combinació de la vectorització dels nostres documents.
També podem clonar l’space que ens agradi al nostre compte i d’aquesta manera tenir-ne un control total i configurar-lo o afegir-li funcionalitats. De fet des de la pròpia pàgina del perfil del model pots desplegar una màquina virtual en alguns dels proveïdors d’infraestructura “cloud” més coneguts. Només hem d’anar a la secció de models, buscar el que volguem i fer clic en “Deploy”
Fitxers estructurats
En qualsevol cas, un cop tinguem una màquina on estigui corrent el model, els passos a seguir són els mateixos. Crearem un petit script que executarem des de una màquina que tingui accés als documents que ens vectoritzi els documents i ens busqui el text d’aquests documents que estigui relacionat amb la pregunta que li estiguem fent. Després agafarem aquest text (el context) i l’adjuntarem amb la nostre pregunta de manera que el model de IA respondrà la nostre pregunta en base al text de context que li haguem passat.
import os
import json
import requests
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.docstore.document import Document
from gradio_client import Client
# Defineix la teva clau d'API de Hugging Face
api_key = "escriu aqui el teu token de Hugging Face"
# Carrega els documents des d'un directori de fitxers JSON
def load_json_documents(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".json"):
with open(os.path.join(directory_path, filename), 'r', encoding='utf-8') as file:
content = json.load(file)
text = ""
for section in content.get('content', {}).values():
if isinstance(section, list):
text += "\n".join(section)
else:
text += section
documents.append(Document(page_content=text, metadata={"title": content.get("title"), "url": content.get("url")}))
return documents
# Vectoritza els documents
def vectorize_documents(documents):
embeddings = HuggingFaceEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
return vectorstore
# Crea un prompt basat en els vectors i la pregunta
def create_prompt_from_vectors(vectorstore, question):
docs = vectorstore.similarity_search(question, k=5)
combined_docs = "\n".join([doc.page_content for doc in docs])
prompt = f"{combined_docs}\n\nPregunta: {question}\nResposta:"
return prompt
# Ruta al directori dels teus documents JSON
document_directory = "C:\\Users\\Naudor\\prova_chatgpt\\documents"
# Carrega i vectoritza els documents
documents = load_json_documents(document_directory)
vectorstore = vectorize_documents(documents)
# Pregunta que vols fer
question = "Quina es l'eficàcia general del model de machine learning que vaig desenvolupar?"
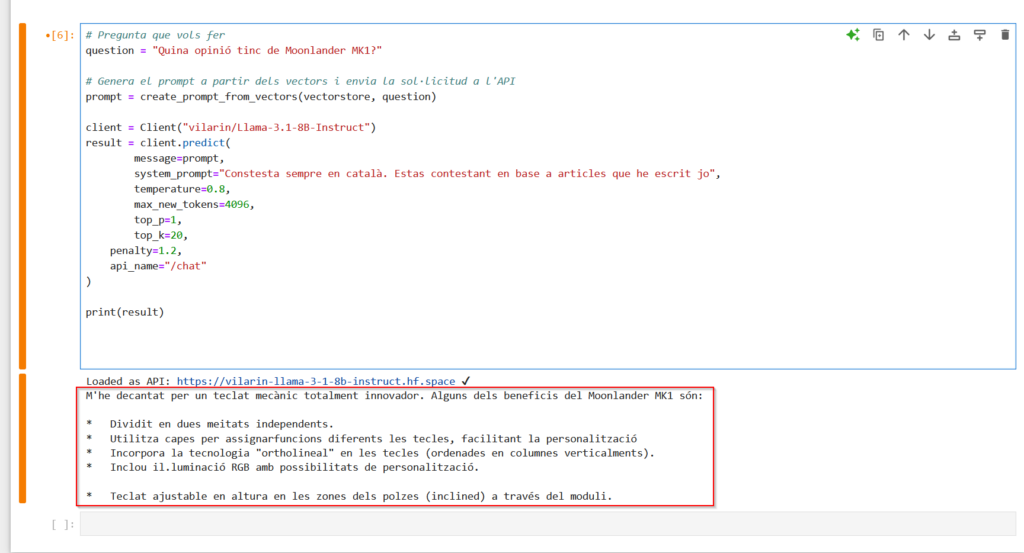
question = "Quina opinió tinc de Moonlander MK1?"
# Genera el prompt a partir dels vectors i envia la sol·licitud a l'API
prompt = create_prompt_from_vectors(vectorstore, question)
client = Client("vilarin/Llama-3.1-8B-Instruct")
result = client.predict(
message=prompt,
system_prompt="Constesta sempre en català. Estas contestant en base a articles que he escrit jo",
temperature=0.8,
max_new_tokens=4096,
top_p=1,
top_k=20,
penalty=1.2,
api_name="/chat"
)
print(result)Si us fixeu aquí si que podem seguir millor els passos que fa.
Seguim tenint una funció que s’encarrega de llegir els fitxers (load_json_documents). Després tenim la “vectorize_documents” que s’encarrega de vectoritzar els documents i crear l’index. Aquí cal que ens fixem un moment en que en la primera linea està creant un objecte que no havíem vist fins ara, els “embeddings”. Per ara direm que es una representació vectorial d’una/es paraules/frases i després aprofundirem una mica més en com es vectorizan els documents i que són els “embeddings”.
Una mica més abaix veiem que la funció “create_prompt_from_vectors” que agafant com a punt de partida la pregunta que li volem fer, ens busca en tots els documents fins a 5 trossos de text que cregui rellevants per la pregunta. Després ens torna el “prompt” que és la concatenació d’aquest trossos més la pregunta que realment estem fent.
Per últim, creem un objecte Client i l’inicialitzem perquè vagi a buscar el model que hi ha en el space escollit e imprimir la resposta del model.
Fitxers no estructurats
Al ser documents no estructurats, s’hauria de pensar i fer proves per cada tipus de document quina estratègia de “partició” (chunks) és més convenient, però s’ha de dir que la més senzilla i que es pot utilitzar per gran part de documents no estructurats, és dividir-ho per pagines que funciona prou be.
Així doncs haurem de fer algunes modificacions al codi que ens vectoritza els documents.
# Carrega els documents PDF
def load_pdf_documents(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".pdf"):
file_path = os.path.join(directory_path, filename)
pages_text = extract_text_from_pdf(file_path)
for i, page_text in enumerate(pages_text):
documents.append(Document(page_content=page_text, metadata={"title": filename, "page_number": i + 1}))
return documents
# Extreu text de cada pàgina d'un fitxer PDF
def extract_text_from_pdf(file_path):
doc = fitz.open(file_path)
pages_text = [doc.load_page(page_num).get_text() for page_num in range(len(doc))]
return pages_textRepetirem la pregunta que hem fet en l’utilització de models GPT, i veiem que l’algoritme ha trobat correctament el “chunk” on hi la informació que necessita el model per poder-nos contestar.
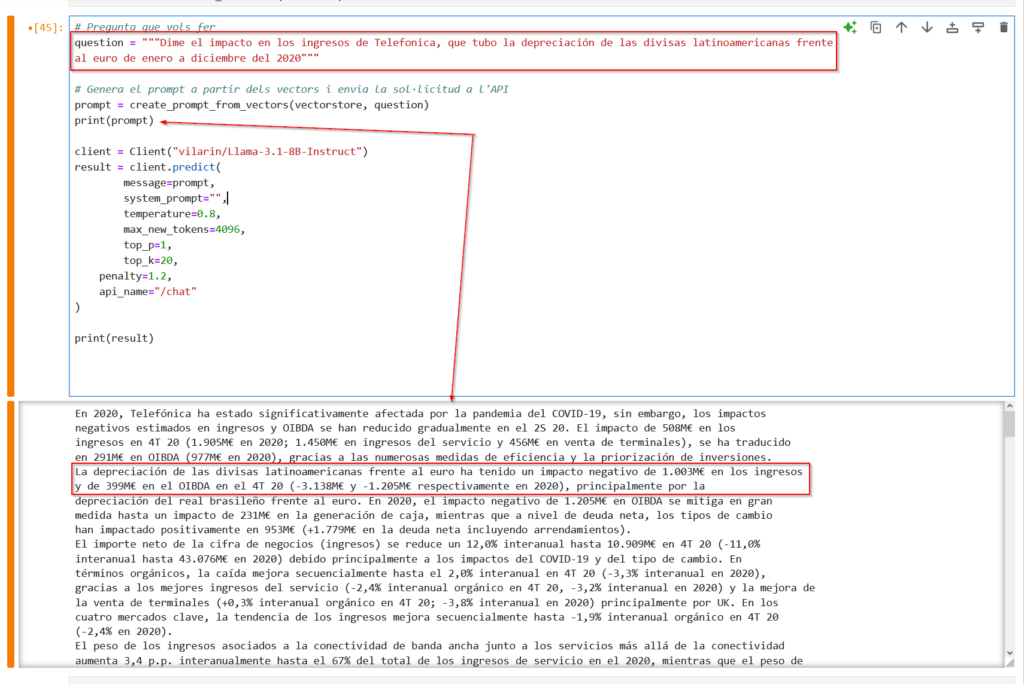
Amb tot aquest context el model em respon el següent:
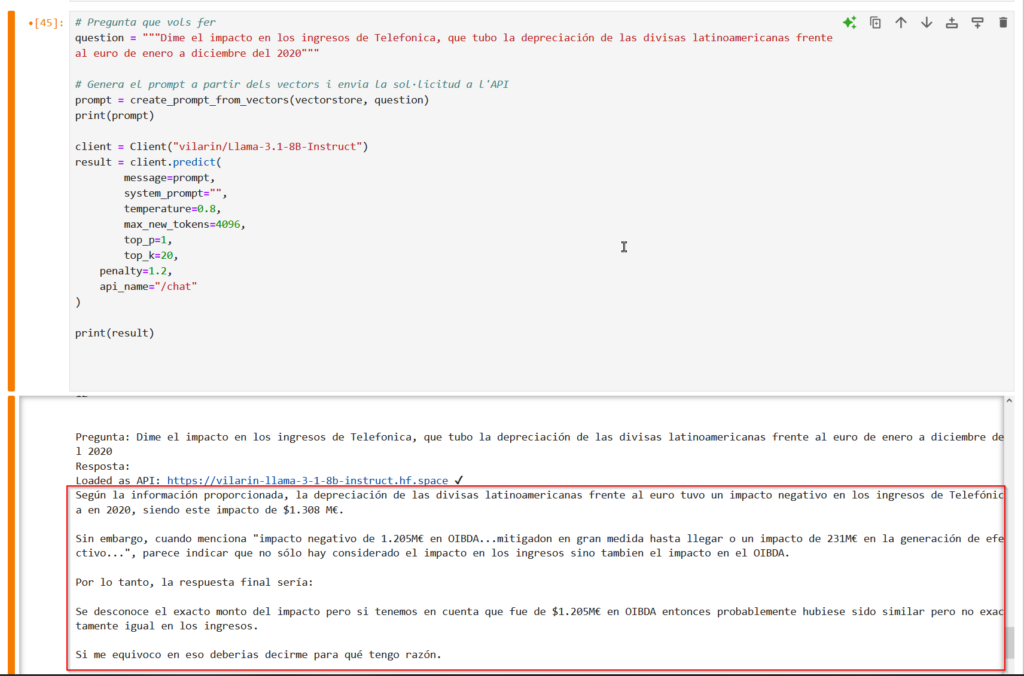
Podeu descarregar tot el codi des del meu repositori.
Procés de vectorització dels documents
Com hem vist durant les proves, primer cal tenir vectoritzats els continguts dels documents en els quals volem cercar. Per fer això, primer s’extreu el contingut del fitxer i es separa en trossos semànticament significatius (chunks).
Cada un d’aquests trossos s’han de convertir en “embeddings” que no és més que representacions vectorials d’objectes en un espai multidimensional (vectors de números de moltíssimes dimensions) i serveixen per transformar dades en un format que els algoritmes puguin utilitzar. Aquest procés es fa per facilitar al màxim possible la cerca ja que si ens endinsem als nivells més profunds del funcionament dels ordinadors, al final, amb l’únic que saben treballar és amb números. Encara que estigueu escrivint una novel·la, editant una imatge o veient un vídeo, al final els ordinadors treballant amb representacions numèriques del que apareix en pantalla.
En l’exemple de l’imatge veiem que tenim diferents paraules (cat, kitten, dog…) i cada una d’elles es representada per un vector. Cada casella del vector és una característica i el valor contingut en la casella marca “com de certa” es la característica per aquella paraula (una puntuació d’un 1 es que aquella paraula compleix amb aquella característica al màxim possible i una puntuació de -1 es que aquella paraula es impossible que pugui complir amb aquella característica).
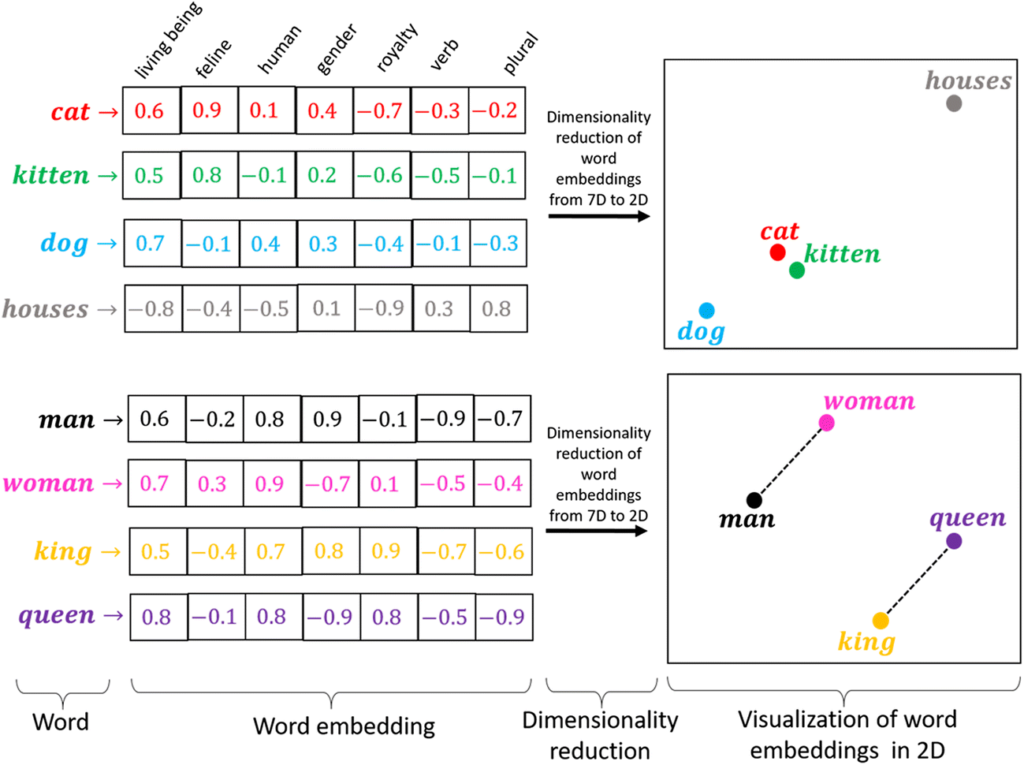
Per exemple un “gat” té una puntuació més alta que un “gatet” pel que fa a la característica de ser un felí, però un “gatet” té una puntuació molt més alta que un “gos” o una “casa”. Tenint en compte totes les característiques ens queda una representació com el gràfic de la dreta, on un “gat” i un “gatet” estan molt aprop, i un “gos” tot i quedar més lluny de les dues primeres paraules, està més a prop d’elles que la paraula “cases”, que no té cap relació amb el resta de paraules.
En el segon gràfic veiem que la distancia entre “home” i “dona” és la mateixa que entre “rei” i “reina”, ja que la única diferencia destacable entre “home” i “dona” es la mateixa que entre “rei” i “reina”, el gènere.
Així doncs si en la meva “prompt” hi hagués la paraula “gat”, els “chunks” que continguin la paraula “gatet” seran considerats més rellevants que els “chunks” que continguin la paraula “casses”.
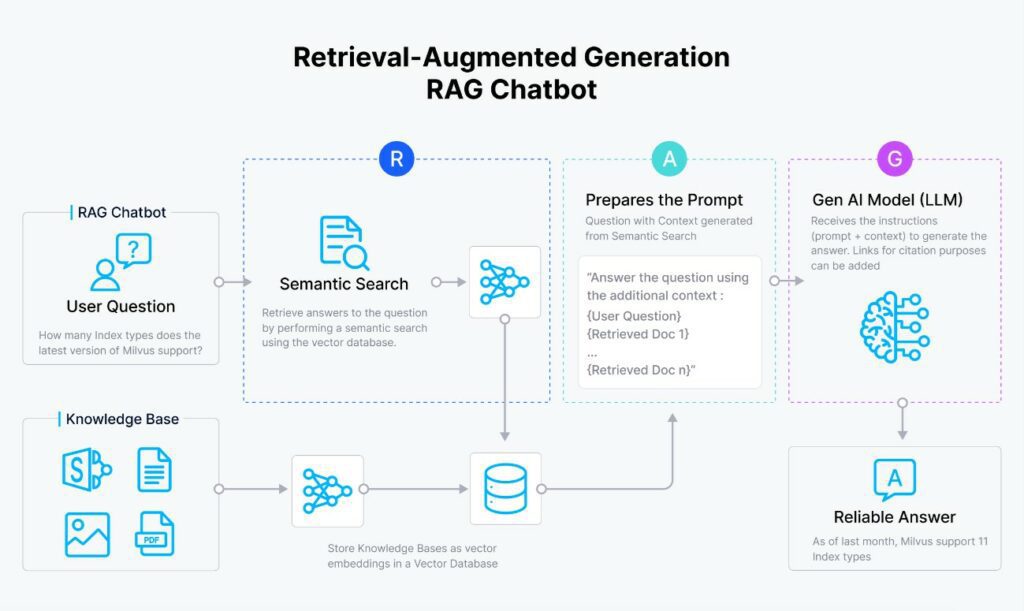
A tot aquest procés se l’anomena RAG (Retrieval-Augmented Generation) i s’està fent servir almenys des de l’aparició de chat GPT 3.5 per evitar les limitacions que tenen els models d’I.A, com per exemple:
- L’accés a informació actualitzada.
- Respostes massa genèriques o fora de context.
- Evitar el fine-tunning constant.
Com es veu en el següent diagrama el RAG consta dels següents passos:
- Es vectoritza la pregunta del usuari.
- Es compara el vector de la pregunta amb tots els vector que hi ha en l’index (típicament una base de dades amb els “embeddings” de cada un dels “chunks”).
- S’agafen els N vectors més semblants i es recuperen el textos original d’aquests.
- Es forma el “prompt” amb el context (els textos del pas anterior) més la pregunta de l’usuari.
- S’envia el “prompt” al model d’I.A i aquest torna la resposta.
Conclusió
Com us comentava son exemples mètodes senzills, ja que tant pel numero de documents, com pel tipus i longitud no val la pena muntar una infraestructura expressament. Si tinguéssim que muntar una aplicació d’aquest tipus en un entorn empresarial hauríem d’afrontar, almenys, les següents qüestions:
- Computació distribuïda: Tindrem moltíssims documents per tant haurem de pensar en plataformes distribuïdes (moltes màquines treballant en paral·lel en el mateix procés, inclús en la mateixa etapa del procés). Les plataformes mes conegudes son Amazon EMR, Amazon EMR, Microsoft Azure HDInsight, Databricks i Hortonworks Data Platform
- Quantitat i formats dels documents: la majoria de documents no estaran estructurats (Words, PDF´s…). S’haurà de buscar la millor manera de “polir” i “tallar” cada tipus de document.
- Emmagatzament i accés: On guardarem tota la informació (tant en “cru” com un cop vectoritzada). Hi han sistemes de base de dades dissenyats específicament per aquests usos. Els sistemes més populars son Amazon Redshift, Google BigQuery, Cloudera Data Platform, Databricks Lakehouse i Snowflake.
- Optimització de la plataforma per tal que no es disparin els costos d’explotació.
- Privacitat: una mica relacionat amb els punts 1 i 2 d’aquesta llista ja que si no volem tenir com un servei extern, estarem exposant la nostre documentació constantment. Per tant, si volem maximitzar/prioritzar aquest punt sempre serà millor en confiar en plataformes que puguin estar allotjades en la infraestructura pròpia i open source.
- Integració amb la resta d’aplicacions empresarials amb el RAG.
Espero que hagueu trobat l’article interessant.