

Recientemente me he introducido en el maravilloso mundo del “machine learning”. Unos cursos de Linkeding Learning y unas horas de dedicación han sido suficientes para entender que es capaz de hacer, posibles usos e incluso de realizar un modelo (muy sencillo) de clasificación automática de texto.
Más allá de una implementación concreta, que veremos en el próximo artículo, la idea es enseñar a grandes rasgos, cuál es la “magia” del Machine Learning y comprender sus posibilidades y limitaciones.
Que es el Machine Learning?
Como se puede ver en el diagrama siguiente, el Machine Learning (aprendizaje automático) es una disciplina dentro de la rama de la Inteligencia Artificial
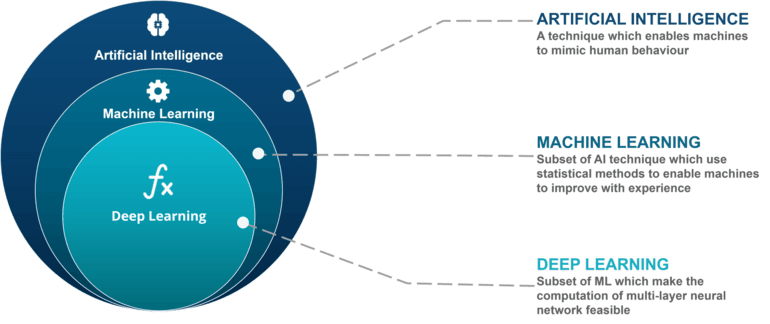
Si tuviera que resumir diría que consiste en la aplicación de algorítmicos matemáticos (especialmente estadísticos) para intentar predecir algo basándose en su histórico. Seguro que con un ejemplo lo ve más claro.
Ejemplos de uso del Machine Learning (ML)
Supongamos que queremos intentar predecir el retraso (más probable) que tendrá un vuelo de Barcelona a Girona. Pensaréis que no hay que hacer un modelo para encontrar una respuesta bastante aproximada a la realidad, que sólo hay que hacer una media de los retrasos de este vuelo de los últimos meses. Pues si no nos hace falta ser muy precisos podría ser suficiente, pero si queremos afinar tendremos que ir más allá y observar más variables. Sin darle muchas vueltas, podría ser interesante tener en cuenta también:
- La hora de despegue: Quizás lo pilotos más cansados de noche que de día.
- El día de la semana: Seguramente el viernes hay más pasajeros y por lo tanto se pueden generar más retrasos.
- El día del mes: Podríamos observar si a principios de mes aumenta o disminuye el número de pasajeros
- El mes: Dependiendo de la época del año habrá más vuelos y por tanto la rapidez con la que nos dan permiso para despegar/aterrizar influirá en la duración del viaje.
- El nombre de los pilotos: Es posible que un piloto sea más propenso a llegar tarde, hablar con los pasajeros, sea más hábil o menos …
- Dirección del viento.
- El modelo del avión: que sea más rápido o menos.
- El tiempo que hace que no se le ha hecho una revisión al avión
Como veis podríamos tener muchas variables en cuenta y generalmente cuantas más variables observamos más fiable será la predicción (hay métodos matemáticos para averiguar qué variables tienen más relación con lo que estamos buscando y en qué la relación es tan débil que no vale la pena tenerlas en cuenta). Con tantos datos ya no es fácil calcular el retraso del vuelo y es aquí es donde una I.A nos puede ayudar.
En este caso, deberíamos tener estructuradas todos los datos de los últimos años y pasarlas por los algoritmos que hayamos decidido a fin de entrenar un modelo que cuando le preguntamos, por ejemplo, si el retraso de un vuelo concreto será mayor a 10 minutos nos conteste que las probabilidades son de un X% .
Debemos tener en cuenta que tenemos que hacer “las preguntas” que puedan ser resueltas por el tipo de algoritmo que hemos escogido y por los datos que le hemos facilitado. Ni podemos preguntar por una variable que no conoce (que no está entre los datos que le hemos pasado) ni podemos esperar una respuesta numérica exacta si el algoritmo con el que estamos trabajando sólo es capaz de darnos un porcentaje de posibilidades.
A pesar de que funciona aplicando algoritmos matemáticos y que los ordenadores sólo saben trabajar con números, con el uso de diferentes técnicas, prácticamente todo se puede transformar en números. Por ejemplo, asignando números a palabras, podemos aplicar las técnicas y algoritmos de ML en textos de modo que seamos capaces de clasificar textos (tweets, artículos de prensa, “papers” …) o entendiendo que las imágenes como matrices de píxeles en las que se indica numéricamente el color de cada uno de ellos.
Diferencia entre Machine Learning y Deep Learning
El “aprendizaje” realizado por un modelo de Machine Learning se puede clasificar en dos grandes grupos: supervisado y no supervisado.
- Supervisado: Cuando requiere que los datos necesarios para entrenar el modelo deben ser etiquetadas o completadas previamente por una persona . Durante este proceso es necesario que una persona indique al modelo que variables tiene que usar. Por ejemplo, para el ejercicio de clasificador de texto, deberemos tener una muestra de textos que hayan sido previamente clasificadas por una persona de manera que le estamos indicando indirectamente al modelo cuantas categorías de textos tenemos y el tipo de estos hay en cada grupo.
- No supervisado : En este caso entrenariamos el modelo con datos “raw” y que por tanto no habría intervención humana para clasificarlas o añadir valor . Este tipo de aprendizaje sobre todo se utiliza para descubrir grupos y relaciones entre las variables. En en el caso de querer agrupar textos, un buen algoritmo de “deep learning” sería capaz de agruparlos sin que una persona las hubiera etiquetado miles de textos previamente. Obviamente no sabría cómo se llama cada grupo (no le estamos pasando ni el nombre de los grupos ni el tipo de texto que hay en cada grupo), pero sería capaz de agruparlas según el texto de cada una de ellas.
En la última década la I.A ha evolucionado mucho gracias al uso del “Deep Learning”. Sigue funcionando en base a algoritmos matemáticos pero en combinaciones mucho más complejas y distribuidas en capas . Es la aproximación que hasta ahora, imita más fielmente el comportamiento del cerebro humano y acostumbrar a representarse como una red de neuronas (red neuronal).
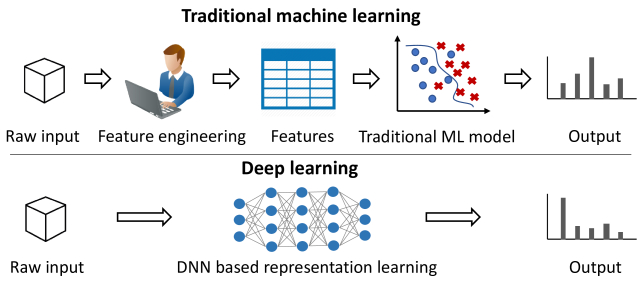
La primera capa se representan las variables de entrada y en las posteriores se van aplicando algoritmos a cada una de estas variables de entrada para finalmente combinar todos estos datos de forma que dé un solo resultado. El ejemplo más clásico es el reconocimiento de objetos.
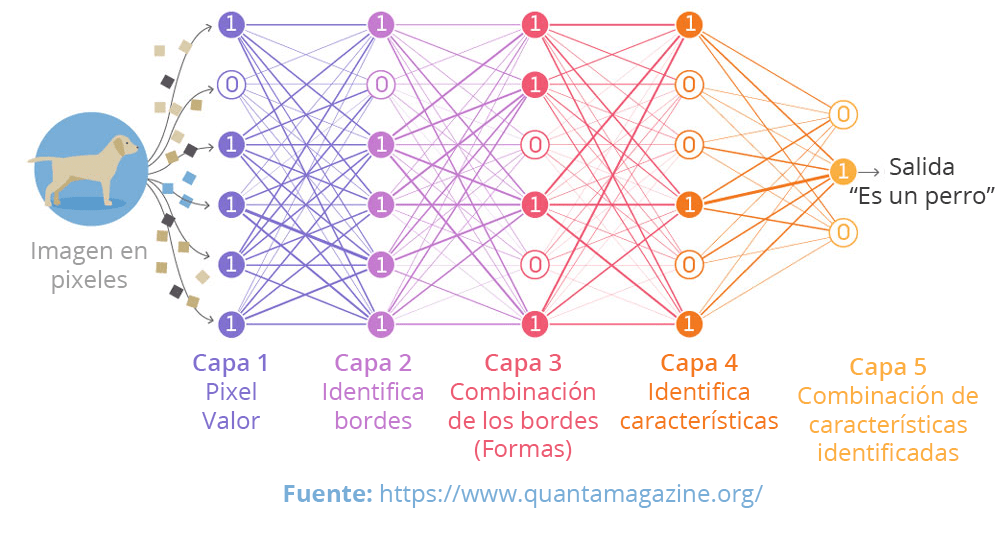
Os dejo el enlace a una masterclass muy interesante que organizaron desde el CIDAI donde David Hurtado Torán (Customer Success Innovation Lead at Microsoft) explica de una forma muy didáctica las diferencias entre Machine Learning / Deep Learning, y “el estado de el arte “actual.
Etapas de un proyecto de ML
Como os comentaba la inicio del artículo, para hacernos una idea más concreta de lo que estamos hablando, comentaremos modelo de clasificación de texto muy sencillo que podríamos aplicar para categorización de incidencias.
Como todo proyecto, se recomienda seguir una serie de etapas para minimizar los posibles errores maximizando así las posibilidades de éxito:
- Definición del objetivo.
- Recopilación y preparación de los datos.
- Elegir el modelo.
- Entrenamiento del modelo.
- Evaluación del modelo.
1. Definición del objetivo.
Imaginemos que trabajamos con un software central donde se reciben todas las incidencias de la empresa, desde la solicitud que pide la creación de un nuevo usuario al sistema, hasta una reclamación sobre un error en una nómina. Para facilitar el cribado de las incidencias y que los especialistas sólo les lleguen las incidencias que pertenecen a su ámbito de conocimiento, todas las incidencias se clasificarán previamente en temáticas / colas.
El objetivo es crear un modelo de ML (de aprendizaje supervisado) que sea capaz de averiguar a qué temática / cola pertenece una nueva incidencia. Como es aprendizaje supervisado deberemos disponer de una cantidad suficientemente grande (del orden de miles) de ejemplos que facilitar al modelo para que aprenda qué tipo de incidencia cada cola.
2. Recopilación y preparación de los datos
Antes de facilitar los datos de ejemplo al modelo deberemos asegurarnos que están en un formato que sea fácil de leer por el ordenador.
Calidad de los datos
Todos los valores para una misma variable deben tener el mismo formato y la misma estructura (normalizar):
- En caso de tener campos numéricos, todos los valores de aquel campo deben estar en el mismo formato, unidad y escala.
- En el caso de los textos tendremos que evitar el texto enriquecido o que se mezcle el texto a analizar con tags HTML, XML etc.
Por ejemplo, en el ejemplo anterior que trataba de adivinar el retraso de los vuelos, si tuviéramos un campo que informa del retraso de los vuelos, que se ha informado por diferentes personas manualmente, podríamos tener valores tan dispares como:
- 12 min
- 12min
- 12
- 720 segundos
- 720sec
- 00: 12: 00h
El modelo sólo entenderá el “12” y no sabrá que hacer con el resto de valores de aquella variable.
Para no complicar el ejemplo y podernos centrar en lo que realmente nos interesa, imaginamos que ya hemos hecho gran parte del trabajo de normalización de los textos y que nos hemos descargado todas las incidencias en un CSV donde aparezcan, al menos, los siguientes campos:
- La descripción de la incidencia.
- En la categoría / cola a la que pertenece.
3. Elección del modelo
Actualmente hay 3 grandes tipos de modelos:
- Clasificación binaria : destinados decir si algo es verdad o falso.
- Clasificación multi-clase : predicción de un valor de entre más de dos posibles valores. Por ejemplo el plato preferido de un cliente.
- Regresión : predice un número concreto, por ejemplo el número de goles que marcará tu equipo de fútbol en un partido concreto.
Dentro de cada tipo modelo hay diferentes algoritmos matemáticos posibles. Por ejemplo hay diferentes algoritmos de encontrar el plato preferido de un cliente y dependerá de la aproximación que quieras hacer y de los datos que tengas el que un algoritmo te genere mejor o peores resultados.
4. Entrenar el modelo
Ahora si, ya lo tenemos todo listo para empezar a programar el entreno del modelo.
Los lenguajes más conocidos para crear proyecto de Machine learning són R, Python y Java. Os recomiendo empezar a aprender ML en Python ya que es el más práctico para dar los primeros pasos ya que existen multitud de librerías que ayudan muchísimo y una cantidad muy grande de ejemplos y documentación.
Además, existe el proyecto JupyterNotebook que permite programar Python desde una interfaz web, pueden ejecutar el código para líneas de manera que puedes ejecutar sólo un parte del código tantas veces como quieras pero manteniendo los estados de las variables y objetos con los valores obtenidos de las líneas anteriores sin tener que ejecutar -las de nuevo. Es muy práctico cuando se trabaja con operaciones que pueden tardar mucho tiempo en ejecutarse como es el caso de los proyectos de ML.
Hasta aquí la parte teórica del ejemplo. Si deseáis ver una implementación en Python muy sencilla de un modelo clasificador de incidencias, he escrito un artículo de cómo hacerlo utilizando NL (Natural Language).
Conclusión
Hemos visto que la tecnología está en un punto que, nos permite predecir mucho mejor que con las técnicas clásicas. Ya hay mucha documentación y herramientas que “democratizan” muchísimo el acceso y que por lo tanto vale la pena incluirla sin “miedo” en los proyectos que puedan salir beneficiados.