

Como os comentaba en el post anterior, vamos a “aterrizar” un ejemplo práctico de cómo implementar un sencillo clasificador de texto, más concretamente un clasificador de incidencias
Escoger lenguaje
Retomando el artículo anterior, los lenguajes más conocidos para crear proyecto de Machine learning son R, Python y Java. No conozco mucho R pero me parece menos versátil que los otros dos. Por otro lado aunque Java es muy conocido y robusto, he encontrado más contenidos sobre ML en Python y además creo que es más práctico para dar los primeros pasos (menos estructura que modificar en cada iteración de prueba / error) por tanto escogeremos este lenguaje para aprender.
Además, existe el proyecto JupyterNotebook que permite programar Python desde una interfaz web, pueden ejecutar el código para líneas de modo que puedes ejecutar sólo un parte del código tantas veces como quieras pero manteniendo los estados de las variables y objetos con los valores obtenidos de las líneas anteriores sin tener que ejecutarlas de nuevo. Es muy práctico cuando se trabaja con operaciones que pueden tardar mucho tiempo en ejecutarse como es el caso de los proyectos de ML.
Los datos
En nuestro ejemplo, contaremos con un archivo CSV con más de 80.000 incidencias correctamente categorizadas.
También podríamos añadir el campo que informa de la persona que ha escrito la incidencia ya que nos puede ayudar a saber de qué tipo de incidencia se trata ya que habitualmente un trabajador pone tipo de incidencia similares. Por ejemplo un trabajador de almacén, por el tipo de trabajo que hace, será más propenso a poner una incidencia al departamento de mantenimiento que el departamento de contabilidad.
Así pues, el archivo tendrá la siguiente estructura:
caller_id: Nombre de la persona que ha escrito la incidencia.
short_description: Asunto de la incidencia o descripción corta.
description: La descripción completa.
assignment_group: Categoría o cola a la que está asignada la incidencia.
Como hablábamos en el artículo anterior es muy importante la calidad de los datos. Para la fuente de donde provienen los datos, en este caso no ha sido necesario hacer limpieza pero si el software guardas el texto en algún tipo de formato enriquecido (por ejemplo HTML) antes de avanzar y entrenar al modelo, deberíamos pulir los datos.
Después de probar diferentes algoritmos (no entraremos en las pruebas realizadas en este artículo), en nuestro ejemplo utilizaremos el algoritmo de clasificación multi-clase llamado “Linear Support Vector Clasificación“
Entrando en materia
Lo primero de todo es leer los datos de entrenamiento, en este caso incidencias
import pandas as pd
import csv
print("Leyendo datos de entrenamiento");
df = pd.read_csv("DataSets/TOTES_LES_INCIDENCIES_v4.csv", encoding = "ISO-8859-1")Como veis tenemos que instalar e importar las librerías Panda, muy conocidas por los programadores de Python. Estas nos permitirán crear un DataFrame (objeto para manipular datos obtenidos de una fuente de datos estructurados) con los datos leídos del archivo CSV donde tenemos todas las incidencias.
Para evitar inconsistencias de datos teniendo en cuenta datos incompletos, se borran del DataFrame las líneas que no tienen todos los campos informados.
df = df.dropna(subset = ["caller_id","short_description","description","assignment_group"])
Con el fin de que el modelo tenga en cuenta el nombre de la persona que ha creado la incidencia, crearemos un campo nuevo en el DataFrame donde uniremos el nombre de esta persona con la del texto de la descripción. Este es el campo con el que trabajaremos a partir de ahora.
df['concatenat'] = df['caller_id'] +'.\r\n'+ df['short_description']
Como el ordenador sólo “entiende” números, debemos asignar uno a cada categoría / cola. El modelo trabaja con estos identificadores y sólo cuando queramos mostrar los resultados podremos volver a relacionar estos identificadores con su descripción correspondiente.
Para hacerlo correctamente debemos hacerlo con la función factorize del dataFrame que nos creará una nueva columna en el DataFrame con el numero que le corresponde a la categoría a la que esta asignada la incidencia
df['category_id'] = df['assignment_group'].factorize()[0]
Antes de comenzar con algoritmos reduciremos el número de palabras con las que deberá trabajar.
Primero una función lambda para convertir todas las mayúsculas a minúsculas por lo que la misma palabra con o sin mayúsculas no pueda ser interpretada como dos palabras diferentes.
Después utilizaremos la librería Spacy para obtener la lista de STOP_WORDS correspondiente al idioma de los texto, en nuestro caso, el español. Esta lista contiene artículos, saludos frecuentes, signos de puntuación … palabras que extraeremos del texto con el fin de optimizar el entrenamiento del modelo.
from spacy.lang.es.stop_words import STOP_WORDS as es_stop
from io import StringIO
import string
df['concatenat'] = df['concatenat'].apply(lambda fila: fila.lower())
final_stopwords_list = list(es_stop)
final_stopwords_list.append('\r\n')
final_stopwords_list.append(string.punctuation)Y ahora llegamos a una de las partes más importantes del entrenamiento de un modelo ML basado en Natural Language (NL), la transformación de las palabras en vectores de números. En este caso el mejor algoritmo que hemos encontrado es el de hacerlo en base a la frecuencia en la que aparecen estas palabras en el texto. Por ejemplo para el texto 1 tendremos un vector donde cada palabra ocupa una posición en él y el valor de esta posición es un valor entre 0 y 1 que indica la frecuencia en la que aparece en este texto.
tfidf = TfidfVectorizer(sublinear_tf=True, min_df=5, norm='l2', encoding='latin-1', ngram_range=(1, 2), stop_words=final_stopwords_list,max_features=5000) features = tfidf.fit_transform(df.concatenat).toarray() labels = df.category_id
De los parámetros que le pasamos al constructor cabe destacar:
- ngram_range = el rango de conjuntos de palabras que creemos que tienen significado para ellas solas. En esta caso estamos indicando que analice conjuntos entre 1 y 2 palabras.
- stop_words = listado de palabras que no queremos que analice el fin de optimizar el proceso y no quede contaminado por palabras que no ayudan a clasificar el texto.
- max_features = tamaño máximo del vector de palabras analizadas por cada texto. En caso de disponer de poca memoria RAM se puede tratar de “jugar” con este parámetro.
Por último, preparamos los nombres de las diferentes categorías donde queramos meter nuestros textos en vector asociativos
Ahora ya tenemos los datos preparadas para entrenar el modelo propiamente. Para ello utilizaremos la librería más famosas de ML en Python, la Sklearn. Para este ejemplo, nos interesan dos cosas de esta librería:
- La función train_test_split: nos permite dividir fácilmente todas las incidencias previamente clasificadas, en dos grupos, un grupo que nos servirá para entrenar el modelo y otro grupo que nos servirá para probar el modelo después de ser entrenado y nos indicará que tanto bueno es el modelo clasificando las incidencias. Como veremos en el ejemplo le hemos estipulado que pruebe el modelo con el 20% de los datos de manera que el otro 80% lo usaremos para entrenar el modelo. Obviamente le tendremos que pasar tanto las incidencias como los grupos en el que la ha de clasificar. Como vemos esta función nos devuelve 6 vectores, tres por cada conjunto de datos.
- El algoritmo que usaremos para clasificar las incidencias: En este caso el que mejores resultados he obtenido es el LinearSVC.
Todos los algoritmos de la librería tienen una función “fit” en la que tenemos que pasarle los dos vector de datos de entrenamiento. Una vez entrenado el modelo llamaremos a la función “PREDICT” que probará el modelo con las incidencias del grupo de test. Esto nos permitirá valorar la eficacia que hemos conseguido con este algoritmo de clasificación y los parámetros configurados.
from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVC model = LinearSVC() X_train, X_test, y_train, y_test, indices_train, indices_test = train_test_split(features, labels, df.index, test_size=0.2, random_state=0) model.fit(X_train, y_train) y_pred = model.predict(X_test)
Como se puede ver estas librerías facilitan muchísimo la tarea ya que incorporan muchísimos algoritmos y estandariza el código para utilizarlos.
Evaluación del modelo
Por fin podemos ver el resultado de todo el trabajo previo. Primero obtendremos una lista de los nombres de todas las categorías / temáticas en las que se podían clasificar los textos y posteriormente haremos un “print” de la tabla de métricas correspondiente a los resultados obtenidos
from sklearn import metrics
unic_label_train = df.groupby(['assignment_group'])['assignment_group'].size()
unic_label_train = unic_label_train[unic_label_train].index.get_level_values(0).tolist()
print(metrics.classification_report(y_test, y_pred,
target_names=unic_label_train))Obtendremos una tabla como ésta (he escondido los nombres de las categorías reales ya que estoy usando un conjunto de datos privados)
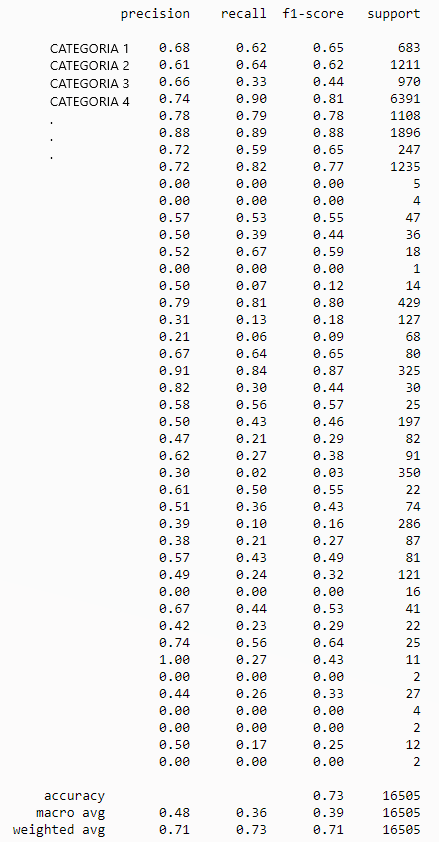
A simple vista veremos una dos secciones, la parte superior donde por cada categoría tendremos sus métricas específicas y la parte inferior donde tenemos el resultado general. El significado de las diferentes columnas es este.
- precisión: Es la relación entre las predicciones correctas y el número total de predicciones correctas previstas (precisión a la hora de predecir casos positivos)
- recall: Es la relación entre las predicciones positivas correctas y el número total de predicciones positivas.
- f1-score: la media de las dos anteriores, vendría a ser la puntuación general de lo bueno que es el modelo en su tarea.
Por lo tanto podemos comprobar que hemos conseguido una eficacia (accuracy) general del 73% de una forma muy sencilla.
Si nos detenemos un poco más veremos que para algunas categorías, tenemos una eficiencia muy baja. Esto puede ser debido a diferentes problemas:
- No hay suficientes incidencias de dicha categoría y por tanto el modelo no se ha entrenado suficientemente bien para identificarlas.
- El textos de las incidencias entre algunas categorías son muy similares y no es capaz de distinguir correctamente a qué grupo pertenece.
- Textos poco específicos (contienen pocas palabras “claves”)
- Falta de optimización de los parámetros configurados en el algoritmo.
Notar que en el entrenamiento del modelo hemos dejado los parámetros por defecto del algoritmo. Normalmente los valores por defecto son los que ofrecen unos valores medios más buenos, pero si quisiéramos profundizar y sacar mejores resultados deberíamos estudiar que hace cada uno de los parámetros del algoritmo (en este caso el LinearSVC) y tratar de encontrar la mejor combinación de estos. Hay métodos automáticos que mediante la “fuerza bruta” te dicen la combinación más óptima de parámetros pero sólo los recomiendo para proyectos que vayan a producción ya que encontrar un mejor combinación requiere una gran cantidad de recursos computacionales y tiempo. Para hacer una aproximación, los parámetros por defecto ofrecen buenos resultados.
Podéis encontrar el codigo entero en mi repositorio de GitHub.
Conclusión
Como hemos visto no se necesitan grandes proyectos para poder aplicar técnicas de Machine Learning, pueden ser proyectos muy modestos, pero lo que si necesitaremos son muchos datos de ejemplo.
Este sólo era un ejemplo muy sencillo y que prácticamente se hace “solo”, únicamente hay que preparar un poco los datos, “concatenar” un par de funciones de las librerías y ver los resultados. Gracias a las librerías que hemos instalado, cambiando muy pocas instrucciones podemos probar con diferentes algoritmos y comprobar qué nos ofrece mejores resultados para nuestro caso.
Puede sorprender que no hemos necesitado grandes conocimientos de estadística para montarlo. Esto es debido a que las librerías que hemos utilizado ya incorporan los algoritmos más útiles y que de seguro cubrirán buena parte de los posibles caso de uso. De todos modos si quisiéramos “jugar” con los datos, comparar algoritmos, afinar las predicciones, etc si que nos hubiera hecho falta unos buenos conocimiento de estadística.
Por ultimo si queréis ver más ejemplos prácticos, existe Kaggle que se una web donde empresas o particulares pueden pedir ayuda en proyectos reales de “machine learning” y la comunidad les puede ayudar de forma desinteresada o interesada (frecuentemente las empresas recompensan los individuos que les ha proporcionado una solución al problema planteado). Normalmente el código se comparte públicamente en la plataforma de manera que sea útil al resto de la comunidad y por tanto es una fuente muy interesante de conocimiento.
Hola Arnau.
Muchas gracias por el articulo, muy bien explicado y me ha ayudado mucho a entender y practicar con datos propios.
Enhorabuena por el blog y espero que continúes y poder seguir leyendo tus artículos.
Muchas gracias Manuel.
Me alegro mucho que te haya servido para aclarar conceptos. No se si podré profundizar mucho más en este tema puesto que no me dedico profesionalmente a ese campo, pero si te gusta trastear con la informática, quizás te interese alguno más de los que escriba.
Si tuvieras dudas sobre algo de lo que escribo o necesitas ayuda para replicarlo no dudes en escribirme 😉
Hasta pronto.
Hola, necesito el archivo CSV las 80.000 incidencias por favor.
uy sí, ahorita rápido te lo va a mandar Arnau. ¿No quieres una taza de café también?
que buen contenido, gracias!!
Gracias Dani, espero verte a menudo por aquí 😉
Hola, al parecer no han actualizado la libreria spacy y hay problemas con la compatibilidad de versión
A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.2 as it may crash.