



Introducción
Sigo haciendo pruebas con la cuenta GPT plus y esta vez quería entender con más detalle el proceso que sigue un modelo de I.A para responder preguntas relacionadas con una documentación que le facilitamos y entender la complejidad/desafíos que supone. Desde hace unos meses se ha popularizado un método muy efectivo llamado RAG (Retrieval-Augmented Generation) y ha llegado el momento de ponerle las manos encima.
Objetivo
Primero, mi intención es que el modelo responda datos de mis artículos de la web. No tengo muchos pero tienen una longitud similar a la que podría ser un documento medio.
Más adelante lo intentaremos hacer con documentos más largos y menos estructurados para acercarnos más a un caso “real” donde una pequeña empresa quiere utilizar un modelo de I.A para que sus trabajadores obtengan información de los documentos corporativos.
Requisitos
Bien, veréis que para el método fácil (utilizar las librerías con modelos de chatGPT) cuenta GPT plus y como es evidente los documentos de los que queréis que responda las preguntas. Cuando veamos cómo hacer lo mismo con modelos open-source solo necesitaréis tener una cuenta en Hugging Face.
Para la prueba con documentos estructurados, necesitaré las URL’s de mis artículos anteriores, pero realmente lo podéis hacer con otros documentos JSON que tengáis. Para la prueba con documentos no estructurados yo me he descargado la presentación de resultados de Telefónica de los últimos 4 años, pero os servirá cualquier archivo PDF.
También necesitaréis un entorno de programación de Python (el lenguaje por excelencia para trabajar con I.A). Yo he utilizado el Jupyter Notebook que es muy práctico para hacer este tipo de prueba pero realmente solo necesitáis instalar Python y tener una aplicación que permita crear/modificar un archivo de texto plano.
Entender la “memoria” de un modelo LLM (Large Language Model)
Antes de entrar en materia es necesario saber cómo funciona la “memoria” de los modelos LLM. Aunque no lo comento en el artículo anterior (donde hablaba de cómo crear un chat GPT personalizado) a los agentes GPT también se les pueden adjuntar documentos para que los tenga en cuenta, pero toda la información/personalización que utilicéis para configurar vuestro agente propio agente, realmente sirve como cabecera de vuestros futuros “prompts” (preguntas) cada vez que hagáis uno.
“Eres un asistente virtual que me ayudarás en las tareas diarias, entre ellas la creación de eventos y recordatorios en mi Google Calendar. Crea un evento en el calendario para el próximo viernes a las 9 y media con el título ‘Crear un nuevo artículo en la web'”


Con un ejemplo se entenderá muy fácilmente. Imaginemos que en la configuración del agente le habéis dicho “Eres un asistente virtual que me ayudarás en las tareas diarias, entre ellas la creación de eventos y recordatorios en mi Google Calendar”. Una vez ya lo tengáis configurado y le queráis pedir “Crea un evento en el calendario para el próximo viernes a las 9 y media con el título ‘Crear un nuevo artículo en la web'”, realmente lo que le estáis diciendo es:
A este “prefijo”, se le llama “contexto”. Y esto funciona perfectamente, pero los modelos tienen limitaciones en cuanto a la cantidad de tokens/palabras que son capaces de tener en el contexto. Los más nuevos (GPT4o) podrían tener un libro de unas 300 páginas aproximadamente como contexto, que es claramente insuficiente para hacer encajar, ni siquiera toda nuestra información personal (emails, documentos legales, facturas, etc…)
Para evitar esta limitación tenemos 2 alternativas:
- Vectorizar los documentos en “embeddings” (vector de datos).
- Que los documentos formen parte de los datos de un proceso “fine-tunning” (re-entrenar el modelo).
A grandes rasgos (más adelante lo explicaré con mucho más detalle) lo que haremos en la primera alternativa será preguntar a un algoritmo de indexación qué documento/s son los más relevantes para la pregunta que estamos haciendo, recuperar el trozo del documento/s que es el realmente relevante y pasarlo como contexto a nuestro modelo para que extraiga la información necesaria para poder respondernos.
El segundo método funciona totalmente diferente. Consiste en hacer un pequeño entrenamiento extra al modelo de I.A para que “memorice” los documentos. Esto permite que no tengamos que preocuparnos de pasar al modelo una parte de los documentos como contexto, sino que el modelo “memorizará” los documentos internamente. Tiene un coste computacional mayor y tiene la desventaja de que estarás entrenándolo con el contenido que tengan los documentos en ese momento, por lo tanto si haces preguntas sobre información contenida en documentos “vivos”, te estará contestando con información desfasada.
Tenéis que tener en cuenta que normalmente las empresas que ofrecen servicios en la nube de inferencia con modelos de I.A suelen facturar por el número de tokens de entrada (contexto + prompt) y los de salida (la respuesta que te da el modelo) por lo tanto la segunda opción es más eficiente en este sentido.
La mejor estrategia a la hora de implementar I.A tanto para el uso doméstico como para el uso empresarial sería hacer un “fine-tunning” de todo aquello que no puede cambiar (histórico) pero ir vectorizando el resto de información.
Preparar los datos
Seguramente lo más complicado de todo el proceso es pulir y transformar los datos. Aunque no son procesos obligatorios sí que son muy recomendables para obtener mejores resultados de la búsqueda.
Para hacer las pruebas con documentos estructurados, como son artículos de mi web (y escribo fantásticamente bien 😉 ) y no muy largos no será necesario, pero habitualmente se debería vigilar estos puntos:
- Eliminación de caracteres especiales y puntuación: Eliminar caracteres que no sean necesarios para el análisis, como puntuación excesiva, emojis, o caracteres no alfabéticos.
- Corrección ortográfica: Corregir errores ortográficos para asegurar la consistencia del texto.
- Normalización de texto: Convertir todo el texto a minúsculas para evitar diferencias causadas por mayúsculas/minúsculas.
- Documentos duplicados: Eliminar documentos que son exactamente iguales.
- Fragmentos duplicados: Eliminar párrafos o frases que se repiten dentro de un mismo documento o entre diferentes documentos.
- Temática: Asegurar que los documentos traten del tema de interés.
- Calidad: Filtrar documentos con poca información, demasiado cortos o de baja calidad.
Con documentos no estructurados es muy recomendable pasarlos por un proceso que les dé una estructura común y convierta el contenido en texto plano, aunque después veremos que este método (RAG) me ha parecido que no es tan sensible al formato como los anteriores (TF-IDF). Si decidimos homogenizar la documentación tendremos que revisar estos asuntos:
- Identificación de títulos, autores, fechas: Extraer y estructurar metadatos importantes de los documentos.
- Clasificación temática: Asignar etiquetas temáticas o categorías a los documentos.
- Formato de texto: Convertir documentos a un formato de texto plano si están en formatos complejos como PDF, Word, HTML, etc.
- Codificación de caracteres: Asegurar que el texto esté en una codificación de caracteres uniforme, como por ejemplo UTF-8.
Para la primera aproximación usaré los artículos de la web que al final son documentos estructurados, pero como tienen elementos que pueden confundir al modelo, los transformaré en un archivo JSON con una estructura muy simple (título del artículo, URL de la fuente y el contenido/texto del artículo)
{
"title": ,
"url": ,
"content": {
"Capítulo 1": [
],
"Capítulo 2": [
],
.
.
.
}
}El transformar los artículos a archivo JSON he utilizado el siguiente código:
import requests
from bs4 import BeautifulSoup
import json
import re
def fetch_article(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extraer el título del artículo
title = soup.find('h1', class_='entry-title').text.strip()
# Extraer el contenido del artículo
content_div = soup.find('div', class_='entry-content')
elements = content_div.find_all(['h2', 'p'])
# Organizo el contenido por capítulos
article_content = {}
current_chapter = "Introduction" #Capítulo por defecto para cualquier texto anterior al primer H2
article_content[current_chapter] = []
for element in elements:
if element.name == 'h2':
current_chapter = element.text.strip()
article_content[current_chapter] = []
elif element.name == 'p':
article_content[current_chapter].append(element.text.strip())
# Preparo la estructura del JSON
article_json = {
"title": title,
"url": url,
"content": article_content
}
return article_json
def extract_last_non_empty_word(url):
# Utilizar una expresión regular para encontrar todas las palabras entre las barras invertidas
matches = re.findall(r'/([^/]*)', url)
# Filtrar las coincidencias para eliminar las vacías
non_empty_matches = [match for match in matches if match]
# Retornar la última palabra no vacía o None si no hay coincidencias
return non_empty_matches[-1] if non_empty_matches else None
def save_article_to_json(article_json, file_path):
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(article_json, f, ensure_ascii=False, indent=4)
print(f"Article saved to {file_path}")
# URLs de los artículos
urls = [
"https://arnaudunjo.com/ca/2024/07/07/creacio-dun-chatgpt-personalitzat-agent-gpt/",
"https://arnaudunjo.com/ca/2023/01/31/generant-codi-amb-gpt-3/",
"https://arnaudunjo.com/ca/2021/10/04/alarma-domestica-amb-raspberry-pi/",
"https://arnaudunjo.com/ca/2021/04/25/introduccio-al-machine-learning-aprenentatge-automatic/",
"https://arnaudunjo.com/ca/2021/04/25/machine-learning-model-classificador-de-textos-en-python/",
"https://arnaudunjo.com/ca/2021/02/11/millorant-la-seguretat-i-la-privacitat-en-les-comunicacions-amb-raspberry-pi/",
"https://arnaudunjo.com/ca/2021/01/13/opinio-moonlander-mk1/",
"https://arnaudunjo.com/ca/2020/12/17/desenvolupament-duna-aplicacio-blockchain-desde-0-amb-python/"
]
for url in urls:
last_word = extract_last_non_empty_word(url)
# Paso el contenido a JSON
article_json = fetch_article(url)
# Guardo el archivo JSON
file_path = last_word + ".json"
save_article_to_json(article_json, file_path)
De todo el script lo complicado es la función que “parsea” el contenido y lo transforma en la estructura que os comentaba (fetch_article). Para resumirlo un poco consiste en invocar un parser de HTML y separar el contenido por los tres tipos de tags HTML que me interesan:
- Los textos en los tags H1 los considero el título.
- Los textos en los tags H2 los considero los capítulos.
- Los textos en los tags P los considero el contenido de cada uno de los capítulos.
Aplico esta función para cada uno de los artículos y guardo el contenido en archivos diferentes con extensión .json
Los archivos generados se guardan con la estructura que comentaba anteriormente, por ejemplo:
{
"title": "Machine Learning: Modelo clasificador de textos en Python",
"url": "https://arnaudunjo.com/ca/2021/04/25/machine-learning-model-classificador-de-textos-en-python/",
"content": {
"Introducción": [
"Como os comentaba en el post anterior, vamos a “aterrizar” un ejemplo práctico de cómo implementar un sencillo clasificador de texto, más concretamente un clasificador de incidencias"
],
"Escoger lenguaje": [
"Volviendo a lo que os comentaba en el anterior artículo, los lenguajes más conocidos para crear proyectos de Machine learning son R, Python y Java. No conozco mucho R pero me parece menos versátil que los otros dos. Por otro lado, aunque Java es muy conocido y robusto, he encontrado más contenidos sobre ML en Python y además creo que es más práctico para dar los primeros pasos (menos estructura que modificar en cada iteración de prueba/error) por tanto escogeremos este lenguaje para aprender.",
"Además, existe el proyecto Jupyter Notebook que permite programar Python desde una interfaz web, pudiendo ejecutar el código por líneas de manera que puedes ejecutar solo una parte del código tantas veces como quieras pero manteniendo los estados de las variables y objetos con los valores obtenidos de las líneas anteriores sin tener que ejecutarlas otra vez. Es muy práctico cuando se trabaja con operaciones que pueden tardar mucho tiempo en ejecutarse como es el caso de los proyectos de ML."
],
"Los datos": [
"Para nuestro ejemplo, contaremos con un archivo CSV con más de 80.000 incidencias correctamente categorizadas.",
"También podríamos añadir el campo que informa de la persona que ha escrito la incidencia ya que nos puede ayudar a saber de qué tipo de incidencia se trata, ya que habitualmente un trabajador pone tipos de incidencia similares. Por ejemplo, un trabajador de almacén, por el tipo de trabajo que hace, será más propenso a poner una incidencia al departamento de mantenimiento que al departamento de contabilidad.",
"Así pues, el archivo tendrá la siguiente estructura:",
"Como hablábamos en el artículo anterior es muy importante la calidad de los datos. Por la fuente de donde provienen los datos, en este caso no ha sido necesario hacer limpieza pero si el software guardase el texto en algún tipo de formato enriquecido (por ejemplo HTML) antes de avanzar y entrenar el modelo, habríamos pulido los datos.",
"Después de probar diferentes algoritmos (no entraremos en las pruebas realizadas en este artículo), en nuestro ejemplo utilizaremos el algoritmo de clasificación multi-clase llamado “Linear Support Vector Classification“"
],
"Entrando en materia": [
"Lo primero de todo es leer los datos de entrenamiento, en este caso incidencias",
"Como veis tenemos que instalar e importar las librerías Panda, muy conocidas por los programadores de Python. Estas nos permitirán crear un DataFrame (objeto para manipular datos obtenidos de una fuente de datos estructurados) con los datos leídos del archivo CSV donde tenemos todas las incidencias.",
"Para evitar inconsistencias de datos teniendo en cuenta datos incompletos, se borran del DataFrame las líneas que no tienen todos los campos informados.",
"Para que el modelo tenga en cuenta el nombre de la persona que ha creado la incidencia, crearemos un campo nuevo en el DataFrame donde uniremos el nombre de esta persona con la del texto de la descripción. Este es el campo con el que trabajaremos a partir de ahora.",
"Como el ordenador solo “entiende” números, tenemos que asignar uno a cada categoría/cola. El modelo trabaja con estos identificadores y solo cuando queramos mostrar los resultados podremos volver a relacionar estos identificadores con su descripción correspondiente.",
"Para hacerlo correctamente debemos hacerlo con la función factorize del dataFrame que nos creará una nueva columna en el DataFrame con el número que le corresponde a la categoría a la que está asignada la incidencia",
"Antes de empezar con algoritmos reduciremos el número de palabras con las que tendrá que trabajar.",
"Primero una función lambda para convertir todas las mayúsculas a minúsculas de manera que la misma palabra con o sin mayúsculas no pueda ser interpretada como dos palabras diferentes.",
"Después utilizaremos la librería Spacy para obtener la lista de STOP_WORDS correspondiente al idioma de los textos, en nuestro caso, el español. Esta lista contiene artículos, saludos frecuentes, signos de puntuación… palabras que extraeremos del texto para optimizar el entrenamiento del modelo.",
"Y ahora llegamos a una de las partes más importantes del entrenamiento de un modelo ML basado en Natural Language (NL), la transformación de las palabras en vectores de números. En este caso el mejor algoritmo que hemos encontrado es el de hacerlo en base a la frecuencia en la que aparecen estas palabras en el texto. Por ejemplo, para el texto 1 tendremos un vector donde cada palabra ocupa una posición en él y el valor de esta posición es un valor entre 0 y 1 que indica la frecuencia en la que aparece en este texto.",
"De los parámetros que le pasamos al constructor cabe destacar:",
"Por último, preparamos los nombres de las diferentes categorías donde querremos encajar nuestros textos en vector asociativos",
"Ahora ya tenemos los datos preparados para entrenar el modelo propiamente. Para hacerlo utilizaremos la librería más famosa de ML en Python, la Sklearn. Para este ejemplo, nos interesan dos cosas de esta librería:",
"Todos los algoritmos de la librería tienen una función “fit” a la que debemos pasarle los dos vector de datos de entrenamiento. Una vez entrenado el modelo llamaremos a la función “predict” que probará el modelo con las incidencias del grupo de test. Esto nos permitirá valorar la eficacia que hemos conseguido con este algoritmo de clasificación y los parámetros configurados.",
"Como se puede ver estas librerías facilitan muchísimo la tarea ya que incorporan muchísimos algoritmos y estandariza el código para utilizarlos."
],
"Evaluación del modelo": [
"Por fin podemos ver el resultado de todo el trabajo previo. Primero obtendremos una lista de los nombres de todas las categorías/temáticas en las que se podían clasificar los textos y posteriormente “imprimiremos” la tabla de métricas correspondiente a los resultados obtenidos",
"Obtendremos una tabla como esta (he ocultado los nombres de las categorías reales ya que estoy usando un conjunto de datos privados)",
"A simple vista veremos una dos secciones, la parte superior donde para cada categoría tendremos sus métricas específicas y la parte inferior donde tenemos el resultado general. El significado de las diferentes columnas es este.",
"Por lo tanto, podemos comprobar que hemos conseguido una eficacia (accuracy) general del 73% de una forma muy sencilla.",
"Si nos detenemos un poco más veremos que para algunas categorías, tenemos una eficiencia muy baja. Esto puede ser debido a diferentes problemas:",
"Notar que en el entrenamiento del modelo hemos dejado los parámetros por defecto del algoritmo. Normalmente los valores por defecto son los que ofrecen unos valores medios más buenos, pero si quisiéramos profundizar y obtener mejores resultados deberíamos estudiar qué hace cada uno de los parámetros del algoritmo (en este caso el LinearSVC) y tratar de encontrar la mejor combinación de estos. Hay métodos automáticos que mediante la “fuerza bruta” te dicen la combinación más óptima de parámetros pero solo los recomiendo para proyectos que vayan a producción ya que encontrar una mejor combinación requiere una gran cantidad de recursos computacionales y tiempo. Para hacer una aproximación, los parámetros por defecto ofrecen buenos resultados.",
"Podéis encontrar el código completo en mi repositorio de GitHub."
],
"Conclusión": [
"Como hemos visto no hacen falta grandes proyectos para poder aplicar técnicas de Machine Learning, pueden ser proyectos muy modestos, pero lo que sí necesitaremos son muchos ejemplos.",
"Este solo era un ejemplo muy sencillo y que prácticamente se hace “solo”, solo hay que preparar un poco los datos, “concatenar” un par de funciones de las librerías y ver los resultados. Gracias a las librerías que hemos instalado, cambiando muy pocas instrucciones podemos probar con diferentes algoritmos y comprobar cuál nos ofrece mejores resultados para nuestro caso.",
"Puede sorprender que no nos han hecho falta grandes conocimientos de estadística para montarlo. Esto se debe a que las librerías que hemos utilizado ya incorporan los algoritmos más útiles y que seguro cubrirán buena parte de los posibles casos de uso. De todos modos, si quisiéramos “jugar” con los datos, comparar algoritmos, afinar las predicciones, etc. sí que nos hubiesen hecho falta unos buenos conocimientos de estadística.",
"Por último, si queréis ver más ejemplos prácticos, existe Kaggle que es una web donde empresas y particulares pueden pedir ayuda en proyectos reales de “machine learning” y la comunidad les puede ayudar de forma desinteresada o interesada (frecuentemente las empresas recompensan los individuos que les ha proporcionado una solución al problema planteado). Normalmente el código se comparte de manera pública para que sea útil al resto de la comunidad y por tanto es una fuente muy interesante de conocimiento.",
""
]
}
}Vale, ahora ya tenemos los datos en archivo JSON ya podemos pasar a indexarlos.
Indexación de los documentos
Con la API de GPT
En Python utilizaremos la librería llama-index que nos hará todo el trabajo, desde leer los contenidos de los documentos hasta devolvernos la respuesta del modelo.
Archivos estructurados
Como veréis es un proceso extremadamente sencillo (dos líneas de código) pero a la vez muy oscuro ya que solo tienes una visión muy global de lo que hace.
import os
import openai
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
from llama_index.core.llms import LLM
from llama_index.llms.openai import OpenAI
import textwrap
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
os.environ["OPENAI_API_KEY"] = "ESCRIBE AQUÍ TU CLAVE API GPT"
# Define el camino de la carpeta que quieres verificar
directory_path = "./storage"
# Utiliza os.path.exists() para comprobar si el camino existe
if os.path.exists(directory_path):
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir=directory_path)
# load index
index = load_index_from_storage(storage_context)
else:
# construyo el índice
documents = SimpleDirectoryReader("documents").load_data()
# lo cargo en memoria
index = VectorStoreIndex.from_documents(documents)
# lo escribo al disco para no tener que volverlo a crear de 0 cada vez
index.storage_context.persist()
# creo un query engine en base a la documentación vectorizada
query_engine = index.as_query_engine()
context = "Responde siempre en catalán."
pregunta = "¿Qué eficiencia global tenía el algoritmo de Machine Learning que desarrollé?"
prompt = context + pregunta
respuesta = query_engine.query(prompt)
print (respuesta)Básicamente, sino existe el índice en el disco duro lo construyo, lo cargo en memoria y lo guardo en el disco duro para no tener que rehacerlo cada vez. Si ya existe el índice simplemente lo cargo en memoria. Después solo se debe obtener el objeto que te permite “preguntar” a los documentos y pasarle el “prompt”.
Como son pocos documentos y relativamente cortos, crear el indexar no ha invertido ni 4 segundos. Para simplemente cargarlo en memoria ha tardado un 1 segundo aproximadamente. Si ponemos 6 documentos en pdf’s de unas 150 páginas tarda unos 50 segundos en vectorizar y cargar en memoria y 16 segundos si únicamente tiene que leer el índice del disco duro y cargarlo en memoria
Si os fijáis este proceso es tan poco transparente que no sabríamos ni que está enviando información de los documentos como contexto al modelo, es casi magia. De hecho, como estamos utilizando los parámetros por defecto, no sabemos ni qué modelo estamos utilizando (GPT 3.5, GPT 4…). Esto en concreto es muy sencillo, solo tenemos que añadir dos líneas, pero sigues sin tener visibilidad de lo que está haciendo.
# Define el motor de consultas con el modelo escogido llm = OpenAI(model="gpt-4o-mini") query_engine = index.as_query_engine(llm=llm) context = "Responde siempre en catalán." pregunta = "¿Qué eficiencia global tenía el algoritmo de Machine Learning que desarrollé?" prompt = context + pregunta respuesta = query_engine.query(prompt) print (respuesta)


Archivos no estructurados
Vamos a aproximarnos un poco más a un caso de uso real, donde muchos documentos no son estructurados (ya sabéis, Word, PDF…). Como os comentaba, me descargué los documentos de presentación de resultados de Telefónica (desde 2020 hasta 2024), que al ser una empresa cotizada en la Bolsa Española, son de dominio público.


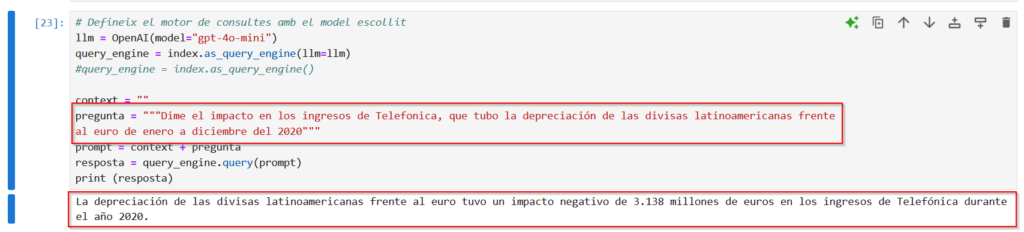
Buscamos qué pregunta podemos hacerle al modelo y encontramos este trozo en la presentación de resultados del año 2020


Y básicamente ya está, no hay que hacer nada más las librerías se encargan de hacer toda la magia. Es igual el tipo de archivo que tenga que leer

Con modelos de código abierto
La verdad es que hice unas pruebas similares hace cosa de un año y era bastante más complicado y el proceso no podía con documentos largos (en mi ordenador). Con las nuevas librerías que han ido surgiendo es bastante más fácil y potente.
La mayor dificultad es por el hecho de que los grandes modelos necesitan más recursos computacionales de lo que tiene mi ordenador de escritorio, por lo tanto, he tenido que buscar la manera de hacer la prueba de concepto sin tener que montar mucha infraestructura. La opción más rápida ha sido utilizar los “spaces” públicos de Hugging Face.
Para quien no conozca Hugging Face es un portal con una enorme comunidad dedicada al Machine Learning y modelos de I.A. Allí podéis probar los últimos modelos que han salido, compararlos, medir su rendimiento, etc.
En este caso nos aprovecharemos de los acuerdos que tienen con diferentes proveedores que ceden infraestructura (máquinas virtuales) en la nube para probar los modelos. Por ejemplo, gracias al acuerdo entre Hugging Face y Gradio podemos disponer de una máquina modesta (2vCPU y 16GB de RAM) totalmente gratuita para hacer pruebas. Cada una de estas máquinas virtuales (realmente son contenedores Docker) y su configuración es lo que forma un “space”. Cada cuenta de usuario en Hugging Face puede tener infinitos(?) “spaces” y en cada uno de ellos tener corriendo un modelo de I.A.
Como somos personas prácticas, buscaremos un space que contenga el modelo que nos gustaría probar (en este caso el modelo LLama 3.1 de 8B)

Una vez dentro nos aparecerá una interfaz de chat (ventana grande donde ver el histórico de la conversación) y un campo de entrada de texto en la parte inferior donde poner el “prompt”. Podemos “jugar” con este chat pero lo que realmente nos interesa es probarlo en combinación de la vectorización de nuestros documentos.
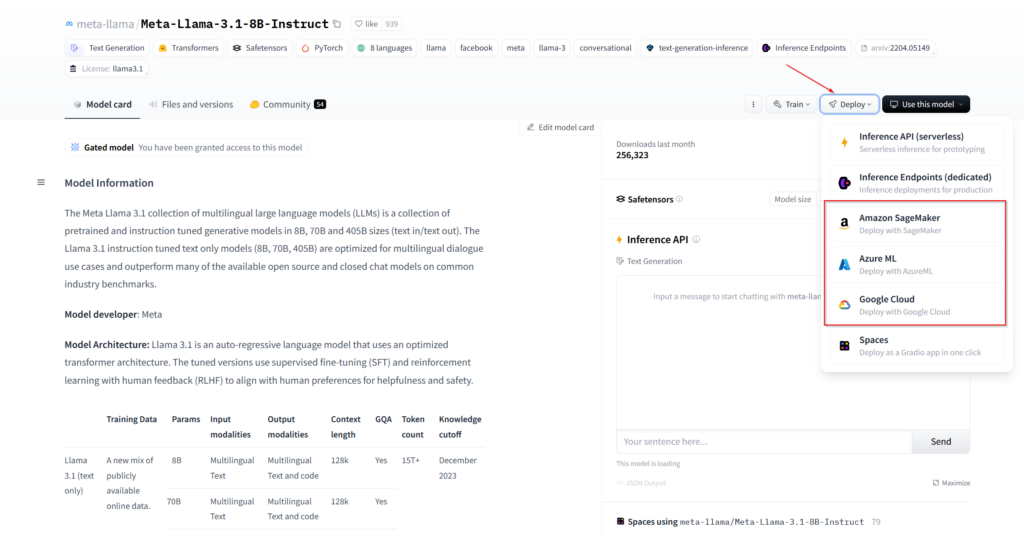
También podemos clonar el space que nos guste en nuestra cuenta y de esta manera tener un control total y configurarlo o añadirle funcionalidades. De hecho, desde la propia página del perfil del modelo puedes desplegar una máquina virtual en algunos de los proveedores de infraestructura “cloud” más conocidos. Solo debemos ir a la sección de modelos, buscar el que queramos y hacer clic en “Deploy”

Archivos estructurados
En cualquier caso, una vez tengamos una máquina donde esté corriendo el modelo, los pasos a seguir son los mismos. Crearemos un pequeño script que ejecutaremos desde una máquina que tenga acceso a los documentos que nos vectorice los documentos y nos busque el texto de estos documentos que esté relacionado con la pregunta que le estemos haciendo. Después cogeremos este texto (el contexto) y lo adjuntaremos con nuestra pregunta de manera que el modelo de IA responderá nuestra pregunta en base al texto de contexto que le hayamos pasado.
import os
import json
import requests
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.docstore.document import Document
from gradio_client import Client
# Define tu clave de API de Hugging Face
api_key = "escribe aquí tu token de Hugging Face"
# Carga los documentos desde un directorio de archivos JSON
def load_json_documents(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".json"):
with open(os.path.join(directory_path, filename), 'r', encoding='utf-8') as file:
content = json.load(file)
text = ""
for section in content.get('content', {}).values():
if isinstance(section, list):
text += "\n".join(section)
else:
text += section
documents.append(Document(page_content=text, metadata={"title": content.get("title"), "url": content.get("url")}))
return documents
# Vectoriza los documentos
def vectorize_documents(documents):
embeddings = HuggingFaceEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
return vectorstore
# Crea un prompt basado en los vectores y la pregunta
def create_prompt_from_vectors(vectorstore, question):
docs = vectorstore.similarity_search(question, k=5)
combined_docs = "\n".join([doc.page_content for doc in docs])
prompt = f"{combined_docs}\n\nPregunta: {question}\nRespuesta:"
return prompt
# Ruta al directorio de tus documentos JSON
document_directory = "C:\\Users\\Naudor\\prova_chatgpt\\documents"
# Carga y vectoriza los documentos
documents = load_json_documents(document_directory)
vectorstore = vectorize_documents(documents)
# Pregunta que quieres hacer
question = "¿Qué eficacia general tiene el modelo de machine learning que desarrollé?"
question = "¿Qué opinión tengo de Moonlander MK1?"
# Genera el prompt a partir de los vectores y envía la solicitud a la API
prompt = create_prompt_from_vectors(vectorstore, question)
client = Client("vilarin/Llama-3.1-8B-Instruct")
result = client.predict(
message=prompt,
system_prompt="Constesta siempre en catalán. Estás contestando en base a artículos que he escrito yo",
temperature=0.8,
max_new_tokens=4096,
top_p=1,
top_k=20,
penalty=1.2,
api_name="/chat"
)
print(result)Si os fijáis aquí sí que podemos seguir mejor los pasos que hace.
Seguimos teniendo una función que se encarga de leer los archivos (load_json_documents). Después tenemos la “vectorize_documents” que se encarga de vectorizar los documentos y crear el índice. Aquí cabe que nos fijemos un momento en que en la primera línea está creando un objeto que no habíamos visto hasta ahora, los “embeddings”. Por ahora diremos que es una representación vectorial de una/s palabras/frases y después profundizaremos un poco más en cómo se vectorizan los documentos y qué son los “embeddings”.
Un poco más abajo vemos que la función “create_prompt_from_vectors” que tomando como punto de partida la pregunta que le queremos hacer, nos busca en todos los documentos hasta 5 trozos de texto que crea relevantes para la pregunta. Después nos devuelve el “prompt” que es la concatenación de estos trozos más la pregunta que realmente estamos haciendo.
Por último, creamos un objeto Client y lo inicializamos para que vaya a buscar el modelo que hay en el space elegido e imprimir la respuesta del modelo.

Archivos no estructurados
Al ser documentos no estructurados, se debería pensar y hacer pruebas para cada tipo de documento qué estrategia de “partición” (chunks) es más conveniente, pero cabe decir que la más sencilla y que se puede utilizar para gran parte de documentos no estructurados, es dividirlo por páginas que funciona bastante bien.
Así pues, tendremos que hacer algunas modificaciones al código que nos vectoriza los documentos.
# Carga los documentos PDF
def load_pdf_documents(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".pdf"):
file_path = os.path.join(directory_path, filename)
pages_text = extract_text_from_pdf(file_path)
for i, page_text in enumerate(pages_text):
documents.append(Document(page_content=page_text, metadata={"title": filename, "page_number": i + 1}))
return documents
# Extrae texto de cada página de un archivo PDF
def extract_text_from_pdf(file_path):
doc = fitz.open(file_path)
pages_text = [doc.load_page(page_num).get_text() for page_num in range(len(doc))]
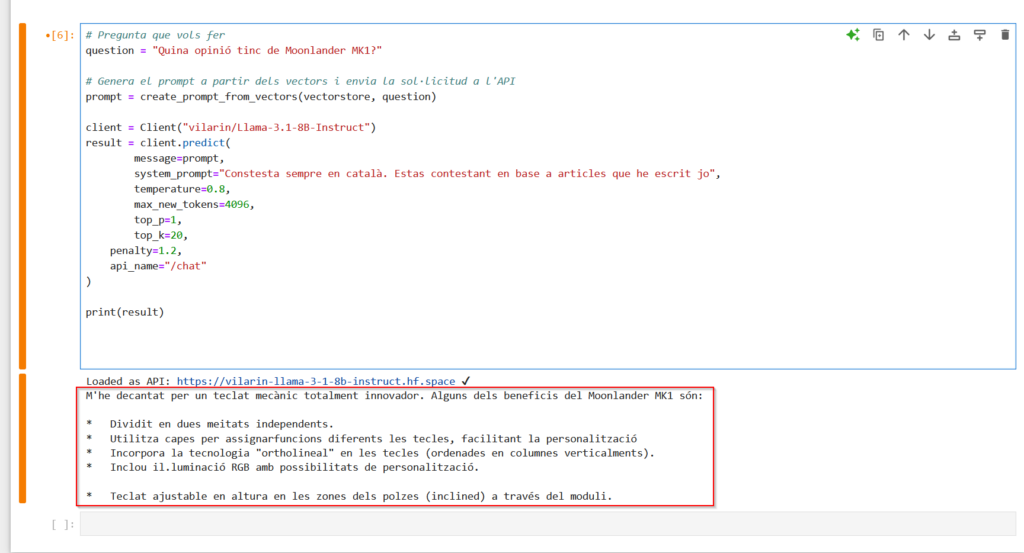
return pages_textRepetiremos la pregunta que hemos hecho en la utilización de modelos GPT, y vemos que el algoritmo ha encontrado correctamente el “chunk” donde está la información que necesita el modelo para poder contestarnos.

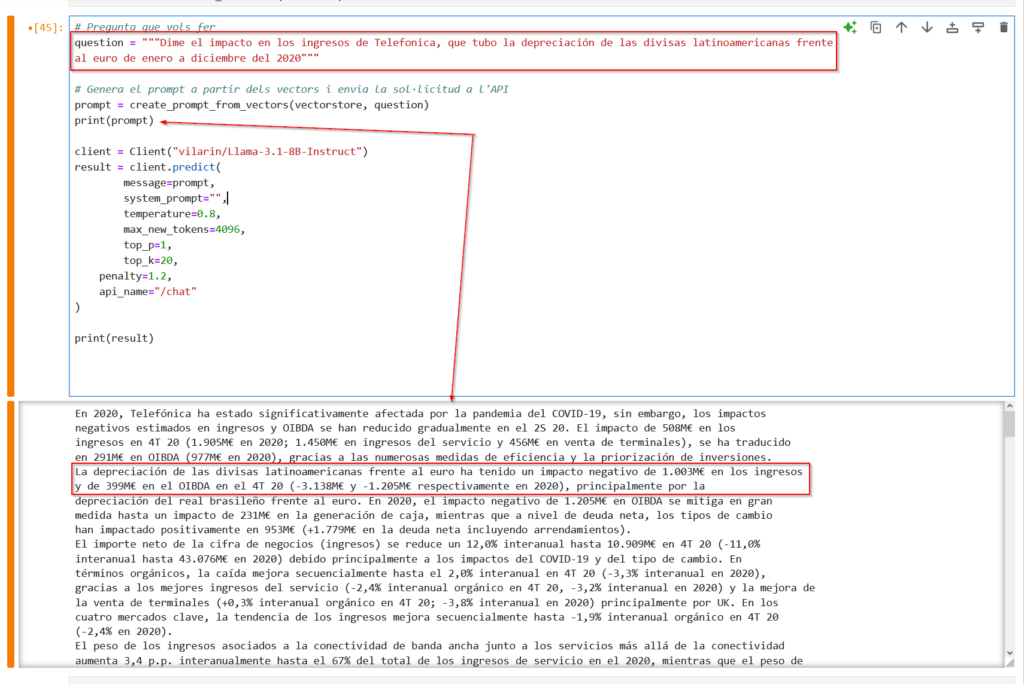
Con todo este contexto el modelo me responde lo siguiente:

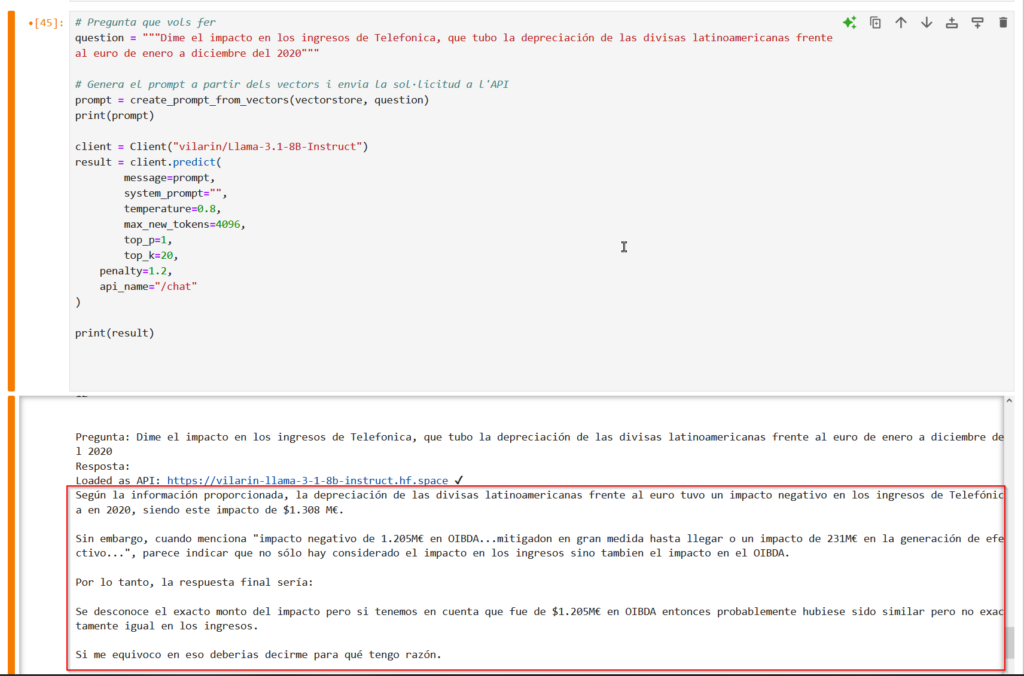
Puedes descargar todo el código desde mi repositorio.
Proceso de vectorización de los documentos
Como hemos visto durante las pruebas, primero hay que tener vectorizados los contenidos de los documentos en los que queremos buscar. Para hacer esto, primero se extrae el contenido del archivo y se separa en trozos semánticamente significativos (chunks).
Cada uno de estos trozos se deben convertir en “embeddings” que no es más que representaciones vectoriales de objetos en un espacio multidimensional (vectores de números de muchísimas dimensiones) y sirven para transformar datos en un formato que los algoritmos puedan utilizar. Este proceso se hace para facilitar al máximo posible la búsqueda ya que si nos adentramos en los niveles más profundos del funcionamiento de los ordenadores, al final, con lo único que saben trabajar es con números. Aunque estéis escribiendo una novela, editando una imagen o viendo un vídeo, al final los ordenadores trabajan con representaciones numéricas de lo que aparece en pantalla.
En el ejemplo de la imagen vemos que tenemos diferentes palabras (cat, kitten, dog…) y cada una de ellas es representada por un vector. Cada casilla del vector es una característica y el valor contenido en la casilla marca “cuán cierta” es la característica para esa palabra (una puntuación de un 1 es que esa palabra cumple con esa característica al máximo posible y una puntuación de -1 es que esa palabra es imposible que pueda cumplir con esa característica).

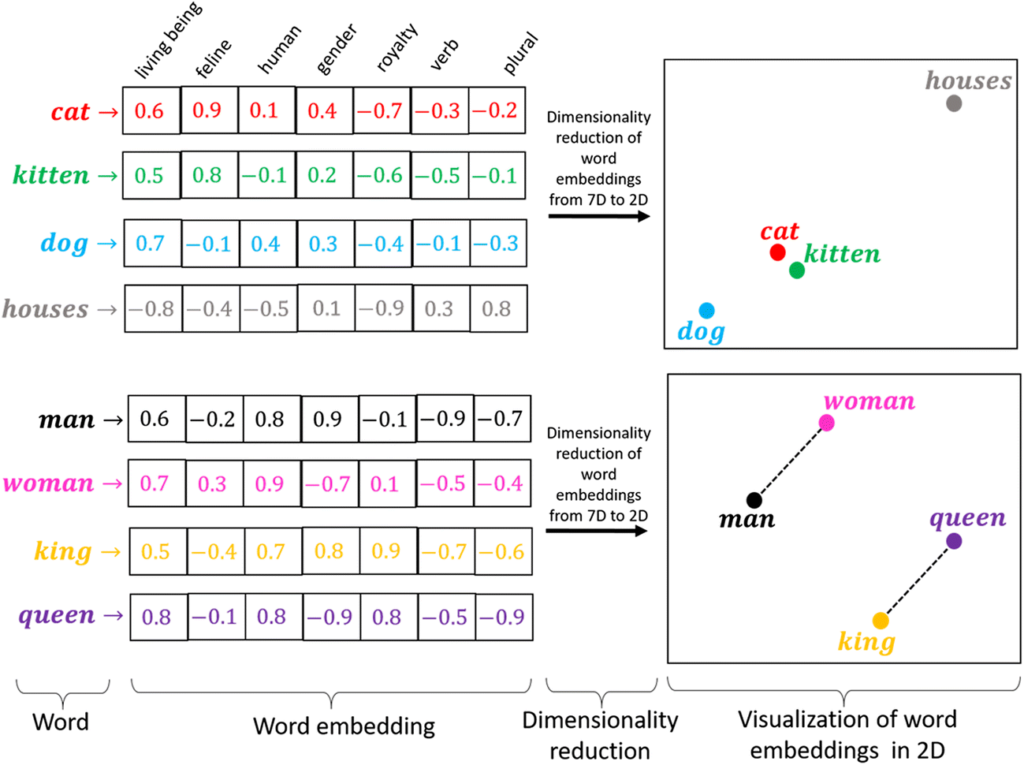
Por ejemplo, un “gato” tiene una puntuación más alta que un “gatito” en cuanto a la característica de ser un felino, pero un “gatito” tiene una puntuación mucho más alta que un “perro” o una “casa”. Teniendo en cuenta todas las características nos queda una representación como el gráfico de la derecha, donde un “gato” y un “gatito” están muy cerca, y un “perro” aunque queda más lejos de las dos primeras palabras, está más cerca de ellas que la palabra “casas”, que no tiene ninguna relación con el resto de palabras.
En el segundo gráfico vemos que la distancia entre “hombre” y “mujer” es la misma que entre “rey” y “reina”, ya que la única diferencia destacable entre “hombre” y “mujer” es la misma que entre “rey” y “reina”, el género.
Así pues, si en mi “prompt” hubiera la palabra “gato”, los “chunks” que contengan la palabra “gatito” serán considerados más relevantes que los “chunks” que contengan la palabra “casas”.
A todo este proceso se le llama RAG (Retrieval-Augmented Generation) y se está utilizando al menos desde la aparición de chat GPT 3.5 para evitar las limitaciones que tienen los modelos de I.A, como por ejemplo:
- El acceso a información actualizada.
- Respuestas demasiado genéricas o fuera de contexto.
- Evitar el fine-tunning constante.
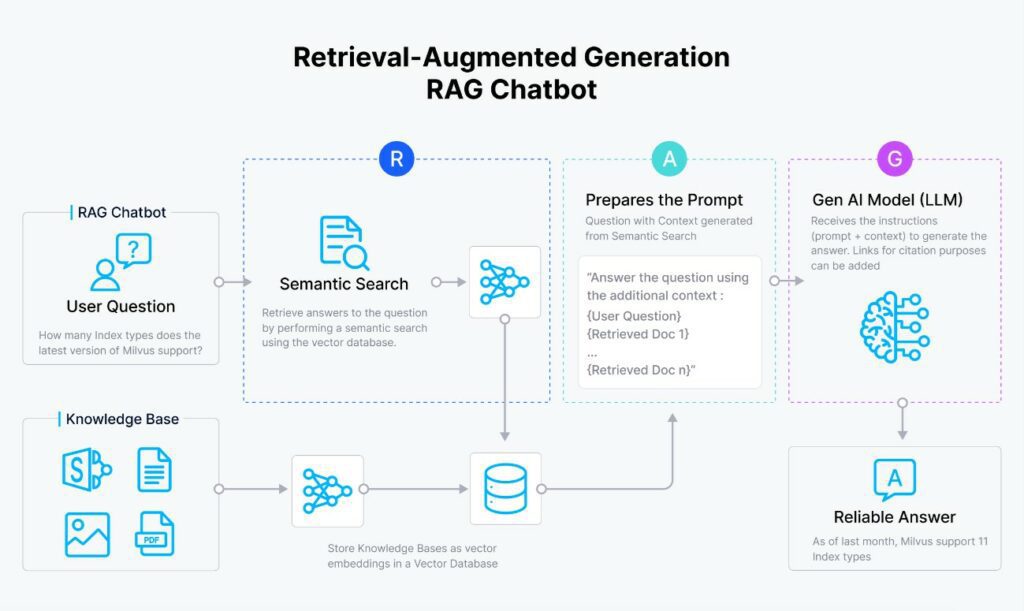
Como se ve en el siguiente diagrama el RAG consta de los siguientes pasos:
- Se vectoriza la pregunta del usuario.
- Se compara el vector de la pregunta con todos los vectores que hay en el índice (típicamente una base de datos con los “embeddings” de cada uno de los “chunks”).
- Se cogen los N vectores más parecidos y se recuperan los textos originales de estos.
- Se forma el “prompt” con el contexto (los textos del paso anterior) más la pregunta del usuario.
- Se envía el “prompt” al modelo de I.A y este devuelve la respuesta.

Conclusión
Como os comentaba son ejemplos métodos sencillos, ya que tanto por el número de documentos, como por el tipo y longitud no vale la pena montar una infraestructura expresamente. Si tuviéramos que montar una aplicación de este tipo en un entorno empresarial tendríamos que afrontar, al menos, las siguientes cuestiones:
- Computación distribuida: Tendremos muchísimos documentos por tanto tendremos que pensar en plataformas distribuidas (muchas máquinas trabajando en paralelo en el mismo proceso, incluso en la misma etapa del proceso). Las plataformas más conocidas son Amazon EMR, Microsoft Azure HDInsight, Databricks y Hortonworks Data Platform
- Cantidad y formatos de los documentos: la mayoría de documentos no estarán estructurados (Words, PDF´s…). Se deberá buscar la mejor manera de “pulir” y “cortar” cada tipo de documento.
- Almacenamiento y acceso: Dónde guardaremos toda la información (tanto en “crudo” como una vez vectorizada). Hay sistemas de base de datos diseñados específicamente para estos usos. Los sistemas más populares son Amazon Redshift, Google BigQuery, Cloudera Data Platform, Databricks Lakehouse y Snowflake.
- Optimización de la plataforma para que no se disparen los costes de explotación.
- Privacidad: un poco relacionado con los puntos 1 y 2 de esta lista ya que si no queremos tener como un servicio externo, estaremos exponiendo nuestra documentación constantemente. Por lo tanto, si queremos maximizar/priorizar este punto siempre será mejor confiar en plataformas que puedan estar alojadas en la infraestructura propia y open source.
- Integración con el resto de aplicaciones empresariales con el RAG.
Espero que hayáis encontrado el artículo interesante.